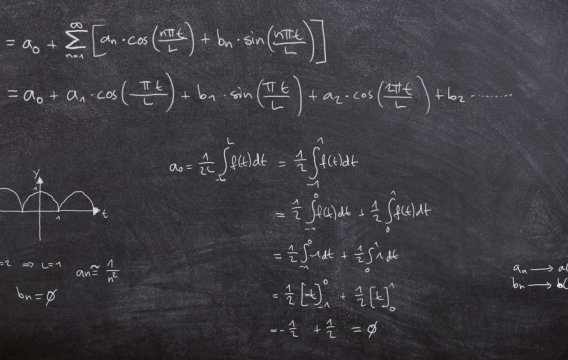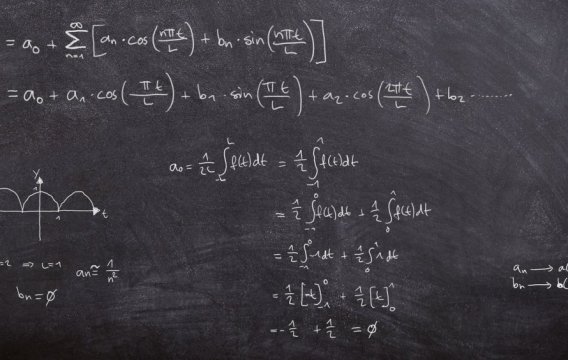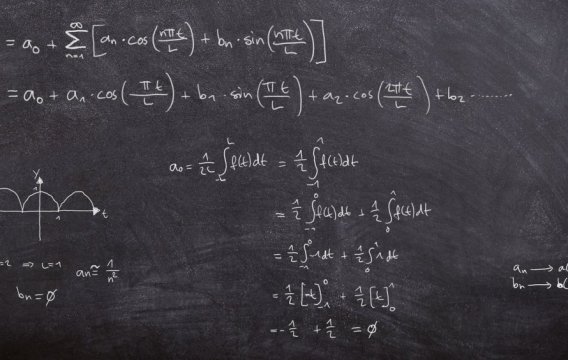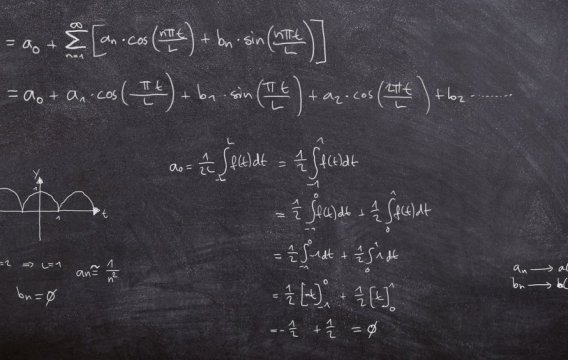„Auto, nebo kozy?“ Tak by se dalo stručně shrnout zadání jednoduché pravděpodobnostní úlohy, jejíž řešení překvapilo i mnohé odborníky. Matička statistika dokáže klamat tělem i duší a pro své vyznavače má připraven nejeden paradox.
Jo, statistik, ten tvrdej chleba má. Za ranního kuropění vyběhne na luka, do lajntuchu opatrně nasbírá půl kila čerstvých dat, pečlivě z nich oláme stopky a doma je rozprostře za pecí k dozrání. Po poledni je obrátí, ve tři shrabe do kupek a pak je až do pozdního soumraku máčí a louhuje, česá i vochluje a rýžovým kartáčem z nich drhne neplatné číslice, až mu čupřinka nadskakuje. A když je za svitu petrolejky konečně začne spřádat do tenounkých vláken reality, zjistí, že mu do nich vítr nafoukal jehličí z borovice.
Ovšem to, co je pro statistika tvrdým chlebíčkem, může být pro někoho jiného voňavým koláčkem pokušení. Skotský básník Andrew Lang kdysi trefně poznamenal: „Politik používá statistiku jako opilec pouliční lampu - k podpoře, nikoliv pro osvětlení.“ A v jeho posudku se skrývá velké zrnko pravdy.
Socio-ekonomické systémy patří k těm nejkomplexnějším a jako takové překypují protiklady, zpětnými vazbami a skrytými proměnnými. Není divu, že leckterý hodnostář si pak v nastalém chaosu zatlačí na tu či onu stranu. A statistika jim k takovým machinacím poskytuje více než dostatek příležitostí. Při nedostatku kontextuálních informací či neopatrném zacházení s daty mohou i v praxi osvědčené postupy dovést nezkušené specialisty k nečekaným paradoxům. Dnes si na dva nejznámější posvítíme jednou starou pouliční lampou. Nejprve se ale podíváme na slíbený oříšek.
Monty Hall problém
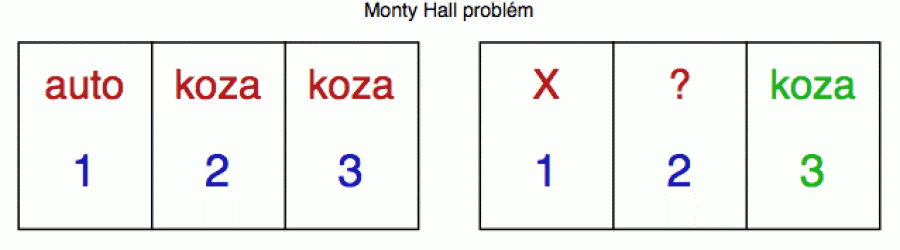
V roce 1975 se v časopisu Scientific American objevil nenápadný článek, ve kterém statistik Steve Selvin popsal pravděpodobnostní hlavolam, volně založený na televizním soutěžním seriálu „Let's Make a Deal“. Jeho moderátor, kanadsko-americký konferenciér a producent Monty Hall, se tak stal bezděčným kmotrem jedné z nejdiskutovanějších pravděpodobnostních hříček své doby. Standardní varianta by se ve stručnosti dala shrnout takto. Představte si, že úspěšně projdete soutěžním pořadem a v jeho závěru vám průvodce ukáže trojici zavřených dveří, za kterými se skrývají tři možné ceny. Za jedněmi je auto (hlavní cena), zatímco za zbývajícími dvěma je pouze koza (tedy jakýsi piškvorek útěchy). Dveře, za kterými je auto, byly zvoleny zcela náhodně a vy je samozřejmě neznáte. Pouze Monty Hall ví, kde je auto a kde kozy (viz červené popisky na obrázku dole vlevo). Vy si tedy jedny dveře víceméně náhodně vyberete (tady vám žádný výpočet nepomůže) a ukážete na ně (na obrázku vpravo jsem vybral dveře č. 1 a zaškrtl je znakem X).
Jenže Monty Hall vám neukáže (alespoň ne hned), co za těmi dveřmi je, ale projeví se jako takový malý pokušitel. Jedny z těch nevybraných dveří otevře - řekněme č. 3 - a ukáže vám, že je za nimi koza. A pak se s nevinným úsměvem obrátí k vám a zeptá se: „Chcete si raději vybrat dveře č. 2, a nebo zůstanete u původní volby (dveře č. 1)?“
Vyplatí se vám svou volbu změnit, nebo ne? To je kruciální otázka této malé statistické habaďůry.
V roce 1990 se v populárním časopise Parade objevil sloupek Marilyn vos Savant
(ve své době držitelky nejvyššího IQ na světě), ve kterém
autorka uvedla, že v této formě problému se vždy vyplatí volbu změnit,
protože pravděpodobnost výhry je pak dvakrát vyšší než při setrvání
na původním výběru. Tento její názor vyvolal bouřlivou (a
povětšinou nesouhlasnou) reakci čtenářů, kteří poukazovali na to,
že i po otevření jedněch dveří jsou šance obou zbývajících na výhru
úplně stejné (fifty-fifty), takže je jedno, zda setrváte na své
původní volbě, anebo se necháte Monty Hallem svést ke změně. Marilyn na
tuto prvotní odezvu zareagovala dalším článkem, ve kterém své stanovisko
potvrdila, a tím mediální bouři rozdmýchala až do intenzity uragánu. Do
redakce došlo na deset tisíc rozhořčených dopisů (mnohé z nich od
držitelů akademických titulů) a problému se obšírně věnoval i známý deník
New York Times (jednu obzvlášť šťavnatou odsuzující reakci si
můžete přečíst na anglické
wiki - v levém výřezu). Nicméně pokud se Monty Hall chová vždy
podle výše popsaného protokolu, tak má pravdu skutečně Marilyn. Můžeme
si to ukázat aplikací Bayesovy věty z minulého
Matykání.
Nejprve značení. A1, A2 a A3 budou jevy, kdy se auto nalézá za dveřmi č. 1, 2 a 3. Podobně O1, O2 a O3 budou jevy, ve kterých Monty Hall otevře příslušné dveře. Opět budeme předpokládat, že jsme si jako počáteční nástřel vybrali dveře č. 1 a že Monty pak otevřel dveře č. 3 (v ostatních případech se to ukáže stejně, jen se musí přečíslovat proměnné). Budou nás tedy zajímat podmíněné pravděpodobnosti
P(A1 | O3) versus P(A2 | O3)
Protože za nějakými dveřmi to auto musí být (a za dvěma být nemůže), můžeme použít minule zmíněný rozklad pravděpodobnosti
P(O3) = P(O3 | A1) * P(A1) + P(O3 | A2) * P(A2) + P(O3 | A3) * P(A3)
což nám dá
P(O3) = (1/2) * (1/3) + 1 * (1/3) + 0 * (1/3) = 1/2
protože pravděpodobnost otevření O3 je 0.5, je-li auto za dveřmi č. 1 (tady si může Monty hodit korunou, zda otevřít dveře č. 2, nebo č. 3), 1.0 je-li auto za dveřmi č. 2 (tady Monty dveře č. 3 otevřít musí, protože jinak by vám daroval auto zadarmo) a 0.0 je-li auto za dveřmi č. 3 (tady Monty dveře ze stejného důvodu otevřít nesmí).
Teď už můžeme obě pravděpodobnosti vyčíslit pomocí Bayesovy věty.
P(A1 | O3) = P(O3 | A1) * P(A1) / P(O3) = (1/2) * (1/3) / (1/2) = 1/3
P(A2 | O3) = P(O3 | A2) * P(A2) / P(O3) = (1) * (1/3) / (1/2) = 2/3
Po otevření třetích dveří je tedy šance nalezení auta za druhými dveřmi skutečně dvojnásobná oproti původně zvoleným dveřím č. 1.
Pokud Bayesovu větu (jako většina obratlovců) zrovna nemusíte, nevěste hlavu. Ono se to dá odhadnout i selským rozumem.
Dobře si rozvažte následující tři možnosti - s tím, že opět budeme (bez újmy na obecnosti) předpokládat předběžný výběr prvních dveří. V první variantě si Monty může vybrat (hodit korunou), které dveře otevře, zatímco v těch dalších už je jeho volba daná. Výsledky obou strategií jsou naznačeny vpravo, a protože ty tři základní možnosti mají stejnou pravděpodobnost, při opakovaném experimentu budete vyhrávat auto dvakrát častěji, změníte-li volbu.

Anebo ještě jednodušeji. Pravděpodobnost auta pro první výběr dveří je 1/3. To auto ale někde být musí (tj. součet pravděpodobností pro všechny dveře musí dát 1). Za těmi dveřmi, které Monty otevřel, auto evidentně není (tam je koza), takže na dveře označené na předchozím obrázku otazníkem zbývají 2/3. Tedy se vyplatí změnit volbu.
Pokud se stále ošíváte, rozmyslete si variantu této hry se 100 dveřmi. Za jedněmi je auto, za 99 zbývajícími kozy. Vy na jedny ukážete, načež Monty 98 těch nevyhrávajících otevře a vám zůstanou dvě zavřené. Ty, které jste si vybrali původně, a pak ještě jedny. I tady byste mohli argumentovat, že obě mají stále stejnou šanci na výhru (50-50), ale myslím, že i zatvrzelým fifty-fiftákům musí být jasné, že na tom rovnostářském argumentu něco nehraje (pro ty druhé dveře máte víc informací).
A super-nevěřící Tomášové si mohou hru samozřejmě nasimulovat s kamarádem (ani se nemusí jmenovat Monty) a se třemi kartami (auto bude třeba žolík) a udělat si vlastní vyhodnoceni obou strategií (změnit versus setrvat). Na stránce Better Explained dokonce najdete online aplikaci, ke které ani kamaráda potřebovat nebudete (a tahle verze umožňuje autosimulaci).
Přesto se lidský mozek zdráhá uvěřit - na řešení si údajně vylámalo zuby i pár matematiků a statistiků. V jedné psychologické studii z roku 1995 se z 228 dotazovaných subjektů pouze 13 % rozhodlo pro změnu volby, přestože (jak jsme si právě ukázali) tato zdvojnásobuje pravděpodobnost výhry. Zajímavé je, že v podobné studii prováděné na holubech se opeřenci velmi rychle naučili, že změna volby je vítězná strategie, což vedlo autory k publikování odborného článku s provokativním titulem „Jsou ptáci chytřejší než matematici?“.
Simpsonův paradox
Trend (respektive jeho směr) má z pohledu praktických aplikací zcela fundamentální význam. Pokud má systém více proměnných (a to ty komplikované mají téměř vždy), je dobré vědět, zda sledované náhodné veličiny rostou ruku v ruce, anebo zda s růstem jedněch ty druhé klesají.
Pokud se zvyšující se dávkou hnojiva rostou výnosy, je na ráj ve stodole zaděláno. Pokud ale s rostoucím přihnojováním výnosy klesají, máme problém.
Statistika proto klade velký důraz na zkoumání skrytých závislostí v náhodných proměnných pomocí regrese či jiných kvantitativních metod. Při tom se často dostaneme do situace, kdy jsou naše objekty rozdělené do nějakých kategorií (tříd) - např. sociologický výzkum může rozdělovat subjekty na muže a ženy, vývozci uhlí mohou sledovat statistiky černého a hnědého zvlášť atd.
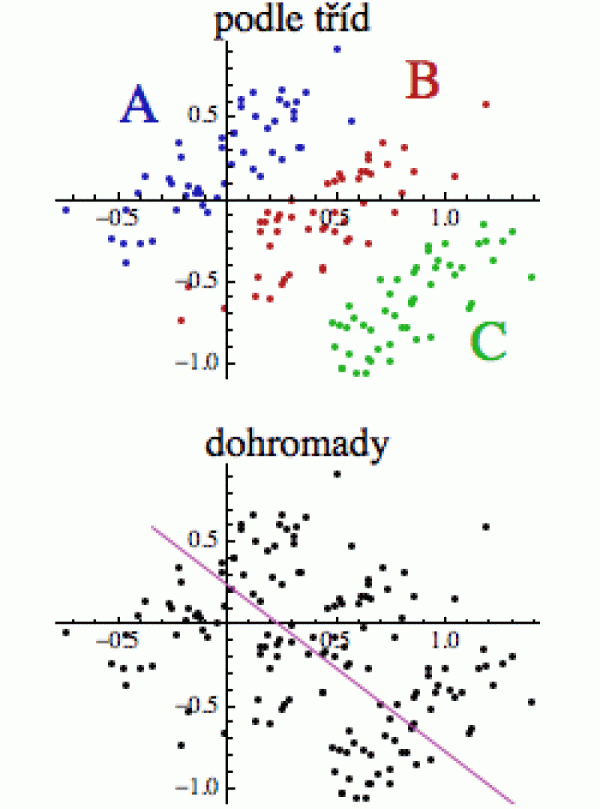
Simpsonův paradox nastává, pokud souhrnné charakteristiky nějakých dat vykazují opačný směr, než ty samé charakteristiky uvažované podle jednotlivých tříd (kategorií) - jak je schematicky znázorněno na obrázku vpravo. Při pohledu na kompletní datový soubor (dole) se zdá, že regresní přímka (fialová) klesá a korelace je tedy záporná (větší hodnota x znamená v průměru menší hodnotu y). Nicméně pokud data roztřídíme podle tříd (kategorií) A, B a C, uvidíme trend přesně opačný: s rostoucím x roste i y (tj. korelace bude kladná).
Abychom nemuseli žonglovat se spojitými proměnnými, ukážeme si jednoduchý příklad s diskrétními veličinami, pocházející z reálné lékařské studie. Představte si, že jste začínající statistik v okresní nemocnici a porovnáváte léčbu ledvinového kamene metodou A (radikálnější) a metodou B (jednodušší). V následující tabulce vidíme zlomky, jejichž čitatel udává celkový počet pacientů podstoupivších danou léčbu, zatímco jmenovatel ukazuje počet uzdravených (v závorce je procento uzdravených pro danou skupinu).
Při pohledu na souhrnná data (tučně) by se mohlo zdát, že metoda B je o něco účinnější (procento uzdravených je o něco vyšší).
Jenže pak zjistíte, že existují dva typy ledvinových kamenů - malé a velké - a když se podíváte na dílčí statistiky (procenta) pro jednotlivé kategorie, zjistíte, že jsou opačné pro obě (!) skupiny. Ať léčíte malé či velké kameny, metoda A vykazuje lepší výsledky, přestože pro obě skupiny dohromady vyhrála metoda B.
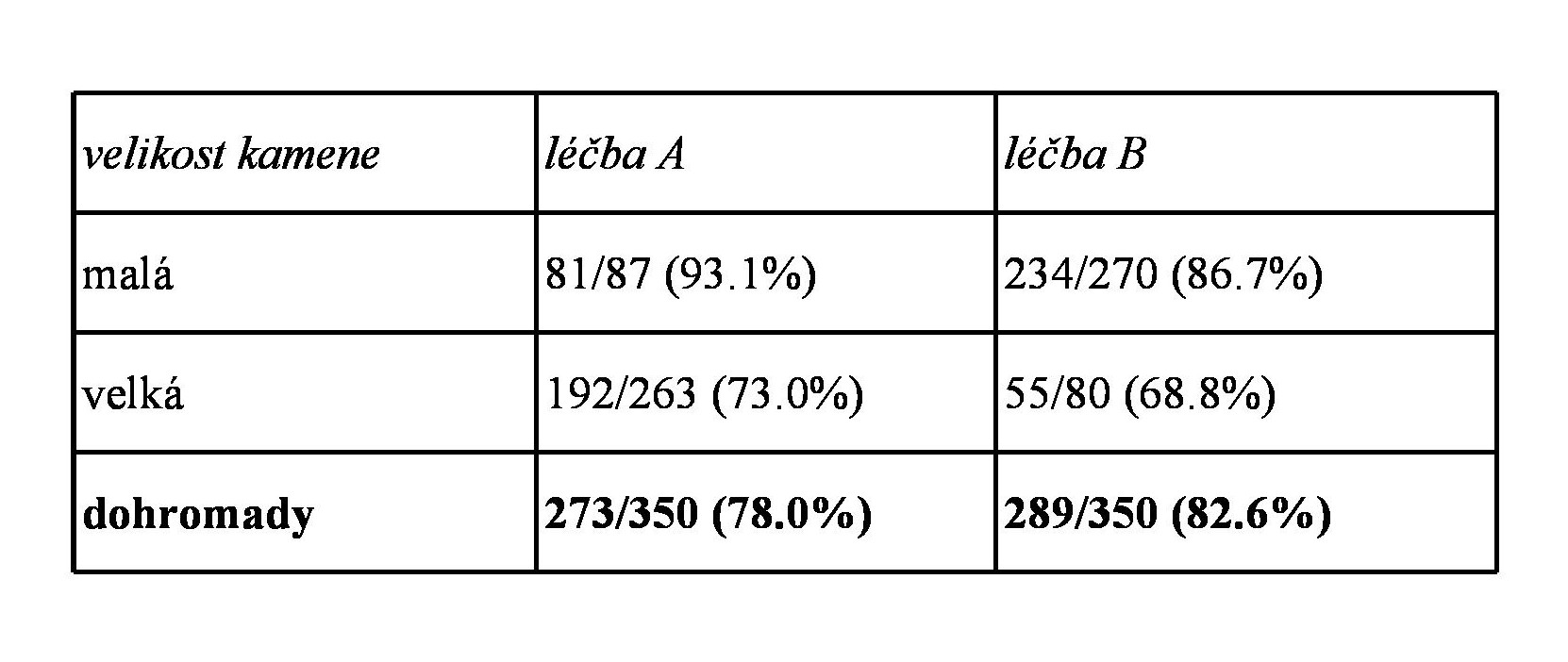
První věc, kterou jako čerstvě vyučený číslozpytec uděláte, je že začnete horečnatě přepočítávat součty v tabulce a ověřovat, že všechno souhlasí. A ono souhlasí. Dohromady je skutečně dohromady. Jak je tedy možné, že slitím obou skupin vznikl obrácený procentuální výsledek?
Z pohledu lékařského je vidět, že obě metody nebyly použity rovnoměrně. Malé kameny (kde se dá očekávat jistější uzdravení) byly většinou nasměrovány na jednodušší léčbu B, zatímco radikálnější léčba A se musela zhusta potýkat s obtížnějšími případy (velké kameny). To pak může vytvořit optický dojem, že v souhrnu je úspěšnější léčba B.
Je to jako byste měli dvě pistole, přesnější A a méně přesnou B. Jenže s tou méně přesnou budete střílet většinou na metrový terč, zatímco s tou přesnější na deseticentimetrový. Pak se bude v souhrnu zdát (když výsledky mechanicky sklepete do jednoho pytle), že pistole B má lepší výsledky, přestože individuální analýzu obou typů terčů vyhraje pistole A.
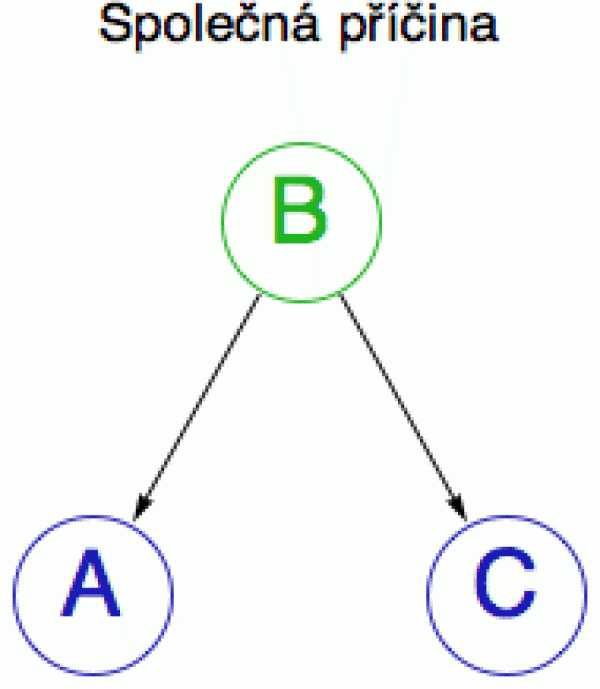
Z matematického pohledu (diagram vpravo) je Simpsonův paradox způsoben existencí skryté proměnné (lurking variable), zde velikost ledvinového kamene (jev B), která ovlivňuje jak zvolenou metodu léčby (jev A), tak šanci na vyléčení (jev C).
Takové proměnné, která ovlivňuje jak A, tak C, se také říká matoucí proměnná (confounder) a hraje klíčovou roli pro pochopení vztahu mezi proměnnými A a C. Zvídavý čtenář si pochopitelně klade otázku, zda by se vliv této matoucí proměnné nedal nějak „odstínit“, jinými slovy, zda by se při agregaci dat nedaly konečné součty upravit nějakým vyrovnávacím faktorem, aby k Simpsonově paradoxu nedocházelo. V principu se to udělat dá (v angličtině se tomu říká „back-door adjustment formula“), a koho by to zajímalo, může se podívat sem.
Simpsonův paradox ukazuje, že v honbě za korelací a regresními koeficienty musíme být opatrní a neposuzovat jen čísla sama o sobě, ale také jejich význam a širší kontext a to se často neobejde bez znalostí specialisty v oboru. Jinak by mohla statistika dohnat slabší povahy k šílenství.
(zde najdete hezkou simulaci Simsonova paradoxu)
Závěrem této sekce ještě malou poznámku o nezávislosti proměnných A a C z předchozího diagramu. Představme si, že A bude počet online zpráv, které za den přečtete, zatímco C bude počet odeslaných emailů. Obě proměnné jsou pochopitelně ovlivňovány počtem hodin strávených na internetu (to bude proměnná B). Pokud o proměnné B nic nevíme a budeme pouze zkoumat A a C, bude se nám zdát, že jsou závislé (jsou pozitivně korelované), protože lidé, kteří tráví na internetu hodně času, posílají víc emailů a současně čtou víc zpráv. Data vynesená v rovině A-C budou mít stoupající trend. Pokud bychom ale hodnotu B znali a zafixovali ji (sledovali bychom například pouze lidi, kteří na internetu tráví plus minus 4 hodiny denně), pak by se zjištěná závislost rozplynula (protože četnost posílání emailů nemá obecně na čtenost zpráv žádný vliv) a pravděpodobně bychom zjistili, že korelace mezi četbou článků (A) a psaním emailů (C) je prakticky nula. To znamená, že ze závislých proměnných se (kontrolou proměnné B) staly nezávislé.
Než se podíváme, k čemu je takový typ uvažování dobrý, představím vám trochu jiný typ statistického paradoxu.
Berksonův paradox
Berksonův paradox je v určitém smyslu opakem Simpsonova paradoxu. Dvě proměnné, které jsou za normálních podmínek nezávislé, se za jistých okolností mohou jevit závislými (nebo se směr závislosti může obrátit).
Předpokládejme, že sociální a technické schopnosti (empatie a šikovnost) jsou v dané populaci zcela nezávislé. Firma F najímá lidi, kteří mají buď jedny, anebo druhé. Na firemním večírku si vaše bystré statistické oko povšimne, že šikovnost a empatie už nejsou nezávislé, ale existuje mezi nimi negativní korelace. Čím více má někdo jedné, tím méně má druhé.
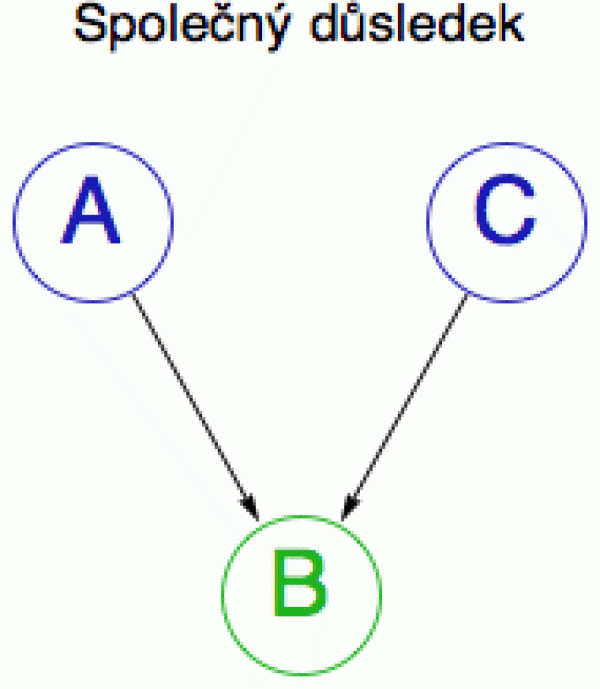
Berksonův paradox je příkladem selektivního biasu (předpojatosti). Na tom večírku nemáme reprezentativní vzorek populace, takže pozorovaná závislost mezi proměnnými je čistě zdánlivá. Schematicky (obrázek vpravo) si můžeme situaci představit jako obrácenou verzi předchozího diagramu: jev A (vysoká empatie) a jev C (vysoká šikovnost) mají oba stejný důsledek: jev B (přijetí do firmy).
Zafixováním proměnné B (přijetí do firmy) docílíme toho, že z nezávislých proměnných se stanou závislé a to je přesný opak toho, co jsme zjistili na konci předchozí sekce.
Abychom si mohli udělat představu, jak silná tato zdánlivá závislost je, provedeme si malou simulaci počítačem.
Jak sociální, tak technické schopnosti ohodnotíme známkou jako ve škole: od 1 (výborné) až po 5 (nedostatečné).
A nyní si náhodně vygenerujeme 100 párů známek (reprezentujících 100 lidí) s tím, že první bude za empatii a druhá za šikovnost.
Tady je pro ilustraci prvních 10 párů známek v naší populaci:
P = (5,3), (3,2), (2,4), (2,2), (1,3), (2,5), (4,4), (1,4), (5,2), (3,2), ...
Když jsem si spočítal korelační koeficient mezi prvními a druhými známkami, dostal jsem 0.02. Tedy prakticky žádná korelace - bodejť by jo, když jsem ty známky generoval náhodně (o tom, zda jsou empatie a šikovnost skutečně nezávislé, se nechci s psychology hádat).
Když jsem si ale z této populace P vybral pouze lidi, jejichž známka byla alespoň v jednom případě buď jednička, nebo dvojka (čímž jsem simuloval přijímací podmínky do firmy F), dostal jsem zápornou korelaci -0.41, a když jsem se omezil pouze na jedničky (tedy mimořádně přísná firma F), vyšla mi korelace mezi oběma sadami známek dokonce -0.59.
(pokud rádi programujete, můžete si vytvořit ještě jemnější klasifikaci schopností - řekněme 0 až 9 - pak si vygenerovat počáteční populaci náhodných dvojic a sledovat, jak se zpřísňující se kritéria pro výběr zaměstnanců - tedy kontrola proměnné B - odráží ve zvyšující se závislosti obou sad známek)
Ještě jednodušeji si tu ztrátu nezávislosti můžeme představit takto. Jevy A a C budou dvě osoby házející mincemi: 0 (panna) a 1 (orel). Jev B bude součtem obou čísel (společný důsledek A a C). I tady pokud o veličině B nic nevíme, tak se nám A a C budou jevit zcela nezávislé (dva lidé hází mincí). Pokud ale budeme vědět, že B je, řekněme, 1, tak A a C už nezávislé nebudou, protože z jedné hodnoty budeme schopni určit druhou (víme-li, že A hodil 1, pak C musel hodit 0, aby byl součet B=1).
A k čemu je tedy celé tohle šachování se závislostí a nezávislostí dobré? To, co nás při pozorování tohoto světa zajímá nejvíce, je kauzalita. Tedy co způsobuje co a kde jsou příčiny a kde důsledky (viz např. známý problém zda kouření způsobuje, anebo nezpůsobuje rakovinu plic).
Tradiční statistická analýza se soustřeďuje na hledání souvztažností (association) a až donedávna se ke kauzalitě (causation) stavěla poněkud odměřeně.
V té dvojici paradoxů jsme ale viděli, že kauzalitu lze v principu detekovat velmi opatrným zkoumáním podmíněné závislosti (tedy závislosti podmíněné nějakým příbuzným jevem B), kterou lze za určitých okolností odvodit z dat.
Tento přístup je v současnosti předmětem poměrně intenzivního výzkumu - jak v přírodních, tak ve společenských vědách - a pokud vás zajímá, doporučuji sérii článků Adama Kellehera (první, druhý a třetí) anebo přímo knihu Causality: the Primer.
Sekce jauvajs: Jak měřit odlišnost rozdělení?
(jen pro otrlé povahy)
V dnešní sekci Jauvajs se vrátím k závěru minulého Matykání, ve kterém jsem se dotkl problému umělé inteligence.
Jednou z prvních dovedností, kterou se každá umělá (i přirozená) inteligence musí naučit, je rozpoznávat objekty. O to se většinou starají softwarové komponenty, kterým říkáme klasifikátory (classifiers).
Zatímco lidé klasifikují objekty většinou binárně - tohle je koza a tamhleto koza není - počítače si pro zařazení objektu do nějaké třídy či kategorie už tak jisté nejsou a jejich výstupy mají většinou formu pravděpodobnostního rozdělení (obvykle mezi konečný počet kategorií) - tedy tento obrázek je na 70 % koza, ale na 20 % by to taky mohl být kamzík a na 5 % antilopa nebo zebra.
Tohle zase nic tak moc revolučního není. Koneckonců i my, lidé, pokud si nejsme jistí, se na svět dokážeme podívat pravděpodobnostně: hele, tohle je na 70 % holubinka sličná, na 20 % holubinka tmavolemá a možná by to mohla být i holubinka odbarvená (10 %).
No a když pak klasifikátor ve své dynamické paměti s těmi možnými rozděleními do tříd různě žongluje, musí být v první řadě schopen říci, jak moc se od sebe liší (tedy jak jsou jednotlivá rozdělení od sebe daleko). Bez solidního pojmu „blízkosti“ se těžko optimalizuje (obzvlášť hledáme-li něco, co je „nejblíž“ realitě).
Pro měření vzdálenosti (odlišnosti) dvou rozdělení P a Q je třeba definovat funkci, obvykle značenou dist (jako distance), která v mnoha případech funguje jako metrika (viz toto Matykání). Čím je dist(P,Q) větší, tím jsou obě rozdělení odlišnější (tj. v abstraktním prostoru všech rozdělení jsou od sebe dále).
Podívejme se na malý příklad. A aby si kozy odpočinuly, zabrousíme do fotbalu. Tři fotbaloví fanoušci se baví, který z týmů elitní šestky má největší šance vyhrát ligu (fungují tedy jako jacísi klasifikátoři sportovního úspěchu). Rozdělení jejich pravděpodobností je znázorněno na dalším obrázku, kde číslo nad sloupkem ukazuje pravděpodobnost (%), že tým X vyhraje titul.
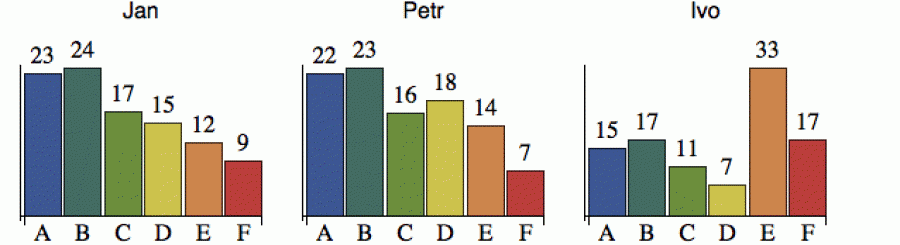
Z obrázku je patrné, že Jan a Petr mají podobný názor. Jejich rozdělení
preferuje tým B, možná i tým A, zatímco týmům E a F přisuzuje malou
šanci. Ivo je ovšem fanoušek týmu E a jeho rozdělení se od obou
předchozích výrazně liší. Rozumně definovaná vzdálenost by tyto vztahy
mezi rozděleními měla odrážet.
Z pohledu matematiky není (diskrétní) rozdělení nic jiného než n-tice čísel
P = (p1, p2, ... pn)
(čísla pi jsou nezáporná a jejich součet je 1)
Chceme tedy definovat funkci, která pozře dvě takové n-tice (procenta samozřejmě převedeme na desetinná čísla) a vyplivne kladné reálné číslo (záporné vzdálenosti nebrat!).
První, co nás napadne, je podívat se na to rozdělení jako na bod v n-rozměrném eukleidovském prostoru a prostě vzít standardní eukleidovskou vzdálenost.
E: dist(P,Q) = sqrt((p1-q1)^2 + (p2-q2)^2 + ... + (pn-qn)^2)
Na tom by nebylo nic špatného, až na to, že jsme nijak nezohlednili fakt, že daná čísla jsou pravděpodobnosti. Proto si statistici ještě vymysleli celou řadu dalších typů vzdáleností, které se používají v různých speciálních situacích. Pro ilustraci vám ukážu tři z nich.
První statistickou je tzv. Hellingerova vzdálenost (pravděpodobnosti jsou většinou malá čísla a ta odmocnina uvnitř X je trochu „načechrá“):
H: dist(P,Q) = sqrt(X) / sqrt(2)
kde X = (sqrt(p1)-sqrt(q1))^2+(sqrt(p2)-sqrt(q2))^2+...+(sqrt(pn)-sqrt(qn))^2
s ní pak úzce souvisí Bhattačarijova vzdálenost
B: dist(P,Q) = -ln(sqrt(p1 * q1)+sqrt(p2 * q2)+...+sqrt(pn * qn))
a konečně KL divergence je založena na statistické entropii (o ní příště)
K: dist(P,Q) = -p1 * ln(q1/p1)-p2 * ln(q2/p2)- ... –pn * ln(qn/pn)
Všechny splňují dist(P,P) = 0, což od slušně vychované vzdálenosti očekáváme.
Tady jsou ty čtyři typy vzdáleností pro tři páry rozdělení z obrázku.
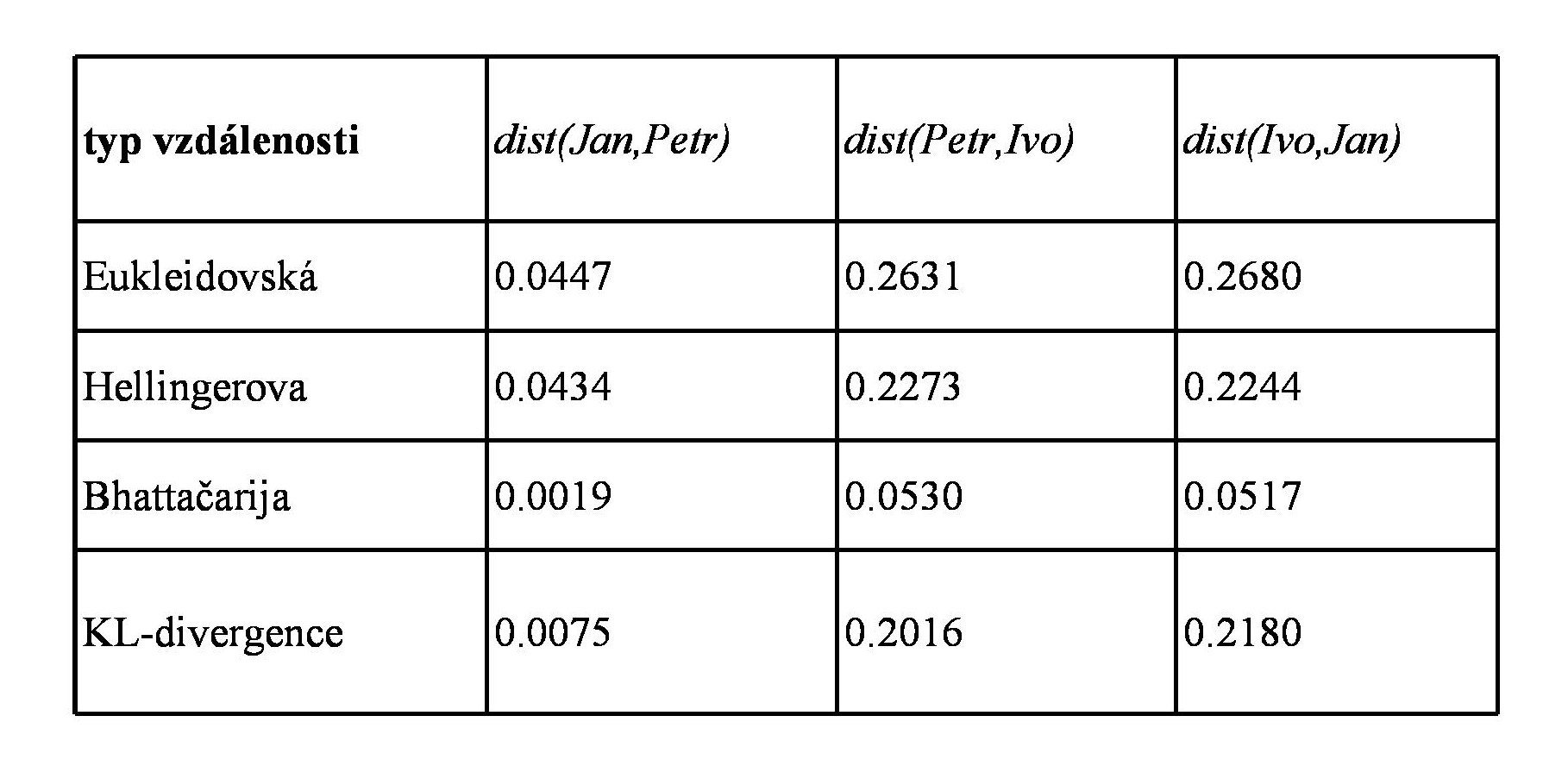
Vidíte, že pro všechny vzdálenosti je rozdělení Jana a Petra poměrně blízko, zatímco Ivo se od obou výrazně liší. Kterou vzdálenost pro daný problém zvolit, je často otázkou empirické zkušenosti a metody pokusů a omylů.
Vzdálenosti se dají definovat i pro spojitá rozdělení, ale tam už se místo sčítání musí integrovat... jéje, zvoní, tak to máte kliku - pro dnešek vám to odpustím.
K problému umělé inteligence se časem vrátím (až se dostaneme k lineární algebře), ale zatím vám alespoň doporučím zajímavý rozhovor s izraelským historikem a filosofem Yuvalem Harari, který se dotýká spíše sociologických a morálních problémů souvisejících s jejím nástupem.
Článek je redakčně upravenou verzí blogového příspěvku na serveru
iDNES.cz. Publikováno s laskavým svolením autora.
Další díly a původní texty jsou dostupné na blogu Jana Řeháčka.