
To takhle stojí devět čtverců před barem a jeden povídá: „Chlapi, opakujte po mně - stanu se menším a ještě menším, až budu nejmenším na celém světě.“ Kolem prochází kružítko a chvíli na ně kouká: „Zase nacvičujete regresi, co?“
Smutno je člověku samotnému a nejinak je tomu i pro matematické proměnné. Vztah mezi dvěma (či více) deterministickými proměnnými zprostředkovává funkce. Vezměme si třeba volný pád. Označíme-li si dráhu padajícího tělesa proměnnou s a dobu, po kterou padá, proměnnou t, bude mezi nimi platit vztah s = gt2/2, ať pustíme dolů hliněnou kuličku nebo skleněnku (odpor vzduchu zanedbáme). To znamená, že známe-li jednu z proměnných, můžeme tu druhou dopočítat.
I u náhodných proměnných nás nezajímá jen, jaké mají rozdělení (a tedy jaké hodnoty od nich můžeme očekávat a s jakou pravděpodobností), ale také zda jsou mezi nimi nějaké smysluplné vztahy.
Pochopitelně nemůžeme očekávat stoprocentně fungující funkce, kde dostaneme vždy stejný výsledek, pokud dosadíme stejné číslo. V náhodných proměnných řádí chaotický šotek, takže se budeme muset spokojit se statistickou interpretací – to, co nám vyjde, bude platit pouze „v průměru“.
Jaký typ vztahu mezi náhodnými proměnnými existuje, se dozvíme z regrese, zatímco korelace nám prozradí, do jaké míry se na tento vztah můžeme spolehnout.
Regrese teoretická
V minulých Matykáních jsme viděli, že náhodné proměnné jsou jakousi směsicí nahodilého a zákonitého. Tomuto základnímu paradigmatu podléhají i vztahy mezi nimi.
Zatímco relace mezi normálními deterministickými veličinami (tedy funkce) jsou obvykle hladké křivky, vztahy mezi náhodnými veličinami vypadají, jako byste podél stezičky rozsypali rýži - s tím, že čím více se vám třese ruka, tím více je v daném vztahu nahodilosti.
Podívejme se na konkrétní případ - dvěma náhodnými veličinami v něm budou výška a váha náhodně vybraného jedince.
Intuitivně je jasné, že tyto dvě veličiny spolu nějakým způsobem souvisí. Obecně platí, že čím je člověk vyšší, tím je těžší. Není to ovšem jednoduchý a jednoznačný výpočet (jako při volném pádu). Když mi řeknete, kolik měříte, v žádném případě z toho vaši váhu nevycucám. Ve hře je spousta dalších skrytých faktorů - jak intenzivně sportujete, zda vám chutná sladké, jaké máte genetické předpoklady atd. Proto nejlepší, v co můžeme doufat, je odhad (popřípadě pravděpodobnost, že skutečná váha bude v určitém rozmezí).
Na obrázku vlevo vidíte výšku h a váhu m pro vzorek 400 náhodně vybraných jedinců. Datové body nejsou po definičním oboru rozházené úplně náhodně, ale v souladu s naším očekáváním vykazují v hrubých rysech přímou úměru. Přesněji - jsou rozházené podél určité přímky (červené), která se pokouší tu nahodilost z dat vyždímat a nahradit ji obecným trendem, odrážejícím průměrné vlastnosti souboru (a v tomto případě i jisté biologické zákonitosti). Pro každý rozumný vzorek dvou náhodných proměnných se taková přímka dá najít explicitně metodou nejmenších čtverců.
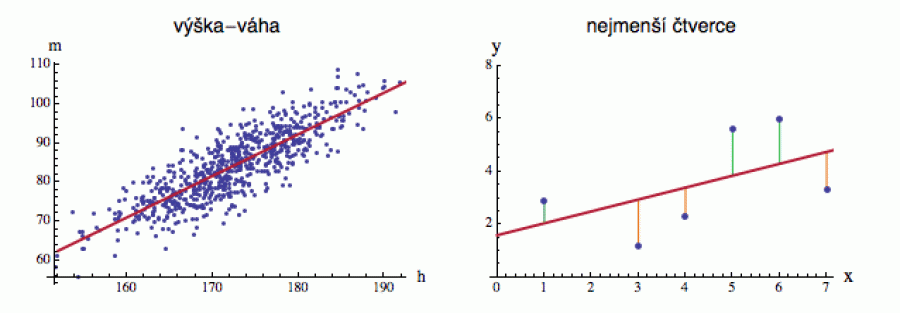
Především je jasné, že závislost mezi výškou a váhou nezjistíme tak,
že si vybereme dva náhodné body a proložíme jimi přímku. Takových
přímek by bylo tolik, kolik je v datovém souboru dvojic, a navíc by se jedna
od druhé výrazně lišily.
Červená aproximační přímka musí záviset na vlastnostech celého souboru. Budeme-li hledat její rovnici ve směrnicovém tvaru y = a + b * x, kde a je průsečík s osou y a b je směrnice přímky, oba parametry musí nějak odrážet hodnoty všech bodů v souboru.
Princip, jak se taková čísla (parametry) najdou, je vcelku jednoduchý.
Pro libovolnou přímku y = a + b * x (ať optimální nebo ne) si můžeme spočítat souhrnnou odchylku datových bodů od ní a pokusit se ji minimalizovat. Nejprve pro každý datový bod (xi, yi) vyčíslíme rozdíl mezi naměřenou (pozorovanou) hodnotou yi a „očekávanou“ hodnotou yi° (tedy y-ovou hodnotou, kterou bychom pro dané xi obdrželi na přímce: yi° = a + b * xi). Těmto dílčím rozdílům yi - yi° se říká „rezidua“ nebo „reziduály“ (v pravé části předchozího obrázku jsou naznačena zelenými a oranžovými úsečkami), a pokud jejich čtverce posčítáme přes všechny body (proto je ve vzorečku to sigma), dostaneme celkovou odchylku pro minimalizaci:
odchylka = Σ (yi - yi°)2 = Σ (yi - a – b * xi)2
Když si to rozmyslíte, zjistíte, že v tom vzorečku jsou dvě neznámé (a, b), a vše ostatní už jsou konkrétní čísla z datového souboru. Protože chceme najít přímku, která daný datový soubor nejlépe aproximuje, budeme její parametry (a, b) hledat tak, aby celková odchylka byla co nejmenší. Hledáme tedy přímku y = a + b * x, která minimalizuje součet čtverců ve vzorečku pro odchylku (odtud název metody). Na technické podrobnosti se podíváme v sekci Jauvajs.
Tomuto procesu se říká regrese a jejím výsledkem je (červená) regresní přímka, která se v praxi používá pro predikci hodnot y, známe-li hodnoty x. Budete-li například dlouhodobě sledovat, jak vaše tržby (y) závisí na prostředcích vložených do reklamy (x), můžete si po nasbírání dostatečného množství dat sestavit regresní přímku (lineární model) a ta vám umožní odhadnout, jak velké tržby y můžete očekávat pro dané reklamní výdaje x.
Ta kouzelná minimalizující přímka má navíc jednu zajímavou vlastnost: kladná a záporná rezidua jsou pro ni v přesné rovnováze. To tedy znamená - jak asi očekáváte - že pro regresní přímku je součet délek zelených úseček (na předchozím obrázku vpravo) stejný jako těch oranžových.
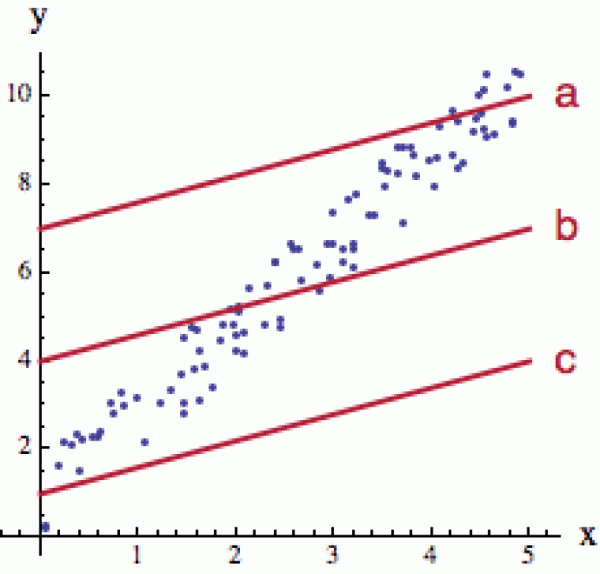
Koumavý čtenář si teď možná pomyslí, proč se ve vzorečku pro celkovou odchylku vůbec babráme s těmi (ne příliš pohodlnými) čtverci. Proč tu regresní přímku nenajdeme rovnou tak, že zjistíme, kde se kladná rezidua (bez čtverců) vyruší s těmi zápornými.
Důvod je patrný z obrázku vpravo. Rovnováha reziduí sama o sobě nestačí. Vezmeme si libovolnou přímku a budeme ji pomalu posunovat shora dolů tak, aby měla stále stejný směr. V pozici (a) mají převahu záporná rezidua (většina bodů je pod přímkou), v pozici (c) kladná a ze spojitosti je tudíž jasné, že někde zhruba v půli cesty (b) se rezidua vyrovnají. Přesto ta přímka v pozici (b) daný datový soubor aproximuje velmi špatně. To, že se kladné odchylky vyruší se zápornými, se dá zařídit triviálně pro každou přímku (jak jsme právě viděli). My potřebujeme něco víc - minimalizovat jejich čtverce. Ty se navzájem nezruší, protože jsou všechny kladné.
Nebo jinak (a trochu zjednodušeně): kvadratická funkce má na rozdíl od lineární tu výhodu, že je konvexní, a tudíž se na ní dá najít extrém. K tomu jsou ty čtverce dobré.
Regrese praktická
Abychom ale nezabloudili příliš hluboko do džungle teoretické statistiky, podíváme se na pár regresních příkladů, kdy je mezi dvěma náhodnými proměnnými zhruba lineární vztah.
První příklad bude diskrétní.
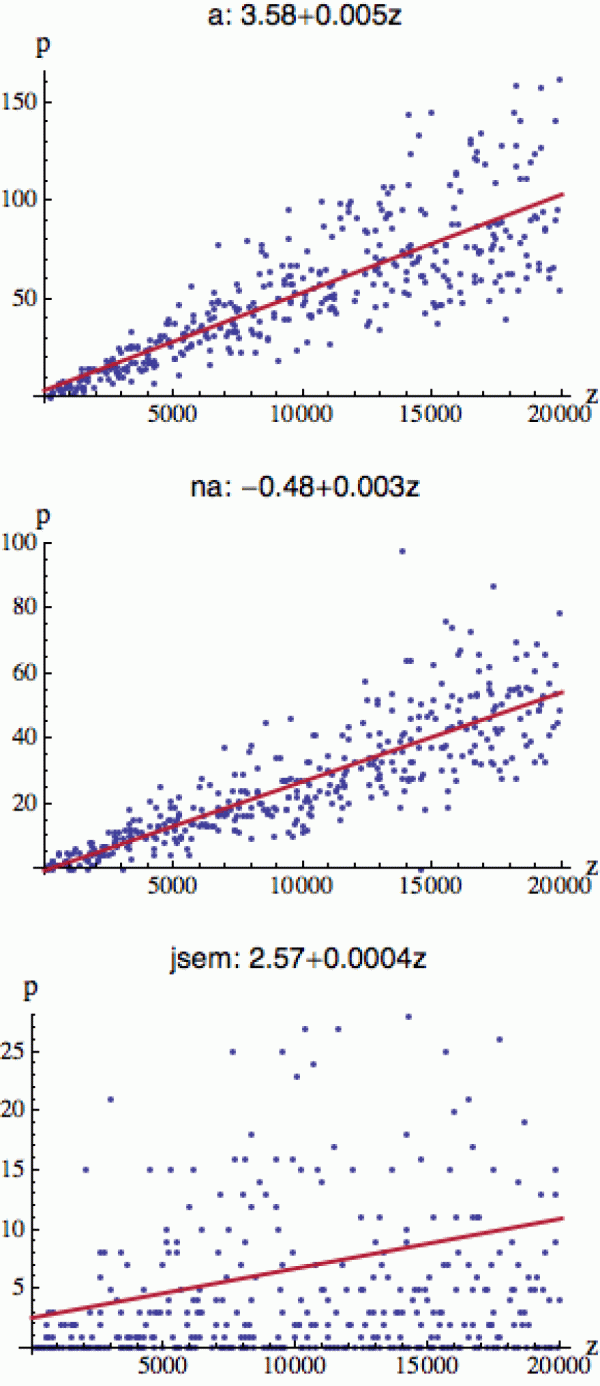
Vezměme si délku článku z (ve znacích) na blogu iDnes a četnost p některých obecných slov, jako je například spojka „a“, předložka „na“ nebo sloveso „jsem“. Čím je článek delší, tím víc sledovaných slov by měl obsahovat (obrázek vpravo).
Ovšem stejně jako v první ukázce (výška/váha) nedostaneme přesnou závislost. Někdo používá spojku „a“ o něco více, někdo o něco méně. Když si ale sestrojíte regresní přímku, dostanete pro její četnost poměrně obstojný odhad y = 3.58 + 0.005z (kde z je počet znaků daného článku). Směrnice v tomto případě zhruba odpovídá průměrné hustotě spojky „a“ v textu.
Všimněte si také, že rezidua (vertikální vzdálenosti jednotlivých bodů od regresní přímky) se zvětšují se zvyšujícím se počtem znaků. Tento efekt je jedním z předmětů reziduální analýzy a hraje důležitou roli při statistickém modelování náhodných procesů.
I předložka „na“ (prostřední obrázek) ještě vykazuje poměrně viditelnou závislost na délce textu, ale u slovesa „jsem“ už je regresní analýza trochu vošajslich. Někteří dokáží i do relativně krátkého článku (vlevo nahoře) nacpat 15-20 „jsem“, zatímco jiní se bez tohoto slova obejdou i u článků nad 10k znaků (vidíte je jako tečky podél osy x, kde je četnost slova „jsem“ rovna nule). Tady už je ten lineární vztah zcela rozmělněn náhodnými vlivy (individuální styl blogera) a regrese v podstatě pozbývá smyslu.
Ten poslední příklad jen podtrhuje důležitost vizuální inspekce při práci s daty. Nestačí jen spočítat regresi, pár průměrů a nějakou tu odchylku. Reálná data jsou komplexní a mnohovrstevnatý objekt a zredukovat je pouze na pár skalárů může zakrýt jejich skutečnou „podstatu“. Anglický statistik Francis Anscombe sestavil v roce 1973 zajímavou čtveřici datových souborů, nazvanou po něm "Anscombův kvartet", která má ty základní statistické parametry (regresní přímka, průměry a směrodatné odchylky) stejné, přestože postihuje zcela jiné typy závislostí. Každému zájemci o statistické zpracování dat doporučuji se s tímto neobvyklým příkladem seznámit.
Druhý příklad bude spojitý a vypůjčím si ho z analýzy akciových trhů. Po skončení každého obchodovacího dne vykazují akcie (a indexy - tedy soubory akcií) určitý procentuální vzestup nebo pokles.
Tyto jdou obvykle ruku v ruce - tedy pokud index vzroste, vzroste i většina akcií v něm a naopak. Každá firma (zastoupená svými akciemi) má ovšem svůj vlastní osud a ten se může v jednotlivostech lišit od makroekonomického chování indexu (nebo ostatních akcií). Vyhodili ředitele, dodavatel jim vypověděl smlouvu, dostali nečekanou vládní zakázku, myši jim přehryzaly klíčové kabely atd.
Na dalším obrázku je každý den na burze znázorněn jedním bodem, jehož x-ová složka ukazuje procentuální vzestup (či propad) nějakého indexu a y-ová složka totéž pro konkretní zvolenou firmu.
V levé části najdete na ose x fond QQQ (což je v podstatě výběr technologického indexu Nasdaq) versus počítačová firma IBM na ose y. V pravé je pak indexový fond SPY (výběr S&P500) versus akcie banky JPMorgan.
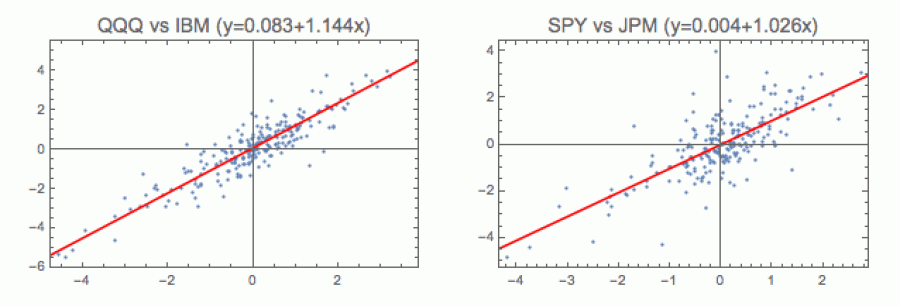
Vidíte, že ve většině případů se ceny vybraných akcií pohybují s indexem, ale občas se chování většiny vzepřou a vyrazí si opačným
směrem (body v severozápadním a jihovýchodním kvadrantu).
Tento způsob analýzy se hojně využívá při vyhodnocování úspěšnosti podílových fondů. Jejich procentuální výsledky (obvykle za měsíc nebo za kvartál) se v porovnání s vhodným indexem vynesou do grafu a regresní přímka nám potom ukáže průměrnou výkonnost fondu.
V její rovnici y = α + βx je beta obvykle indikátorem volatility (těkavosti). Vidíte, že IBM ho má o něco větší než stará zavedená banka JPM. Čím je beta vyšší, tím více sebou daná akcie hází, v porovnání s indexem (její pohyby jsou bouřlivější). U podílových fondů se beta dá uměle navýšit například větší našponovaností (leverage) - tedy de facto tím, že si na své investování půjčíte. Proto se většina manažerů při hodnocení dívá raději na alfa. To regresní beta přímku de facto jen pootočí (máte sice větší vzestupy, ale také větší propady), zatímco alfa ji celou popostrčí. V tom případě nejsou výsledky podílového fondu jen násobkem pohybu indexu, ale (v případě kladného alfa) reprezentují přidanou hodnotu vyplývající ze zkušeností manažera.
Ve finanční hantýrce je alfa tak trochu synonymem investorských schopností. Proto se jeden z nejznámějších blogů pro individuální investory jmenuje Seeking Alpha. Pokud vás to zajímá hlouběji, mrkněte se sem (matematický výklad) anebo sem (investiční úhel pohledu).
Regrese obecná
Regresní přímka je báječná věc, ale má dvě vady na kráse. Za prvé ne všechny vztahy mezi proměnnými (ať náhodnými nebo deterministickými) jsou lineární. A za druhé, u složitějších problémů může závislá proměnná y záviset na více proměnných x. V obou případech se regrese dá naštěstí celkem přirozeně zobecnit.
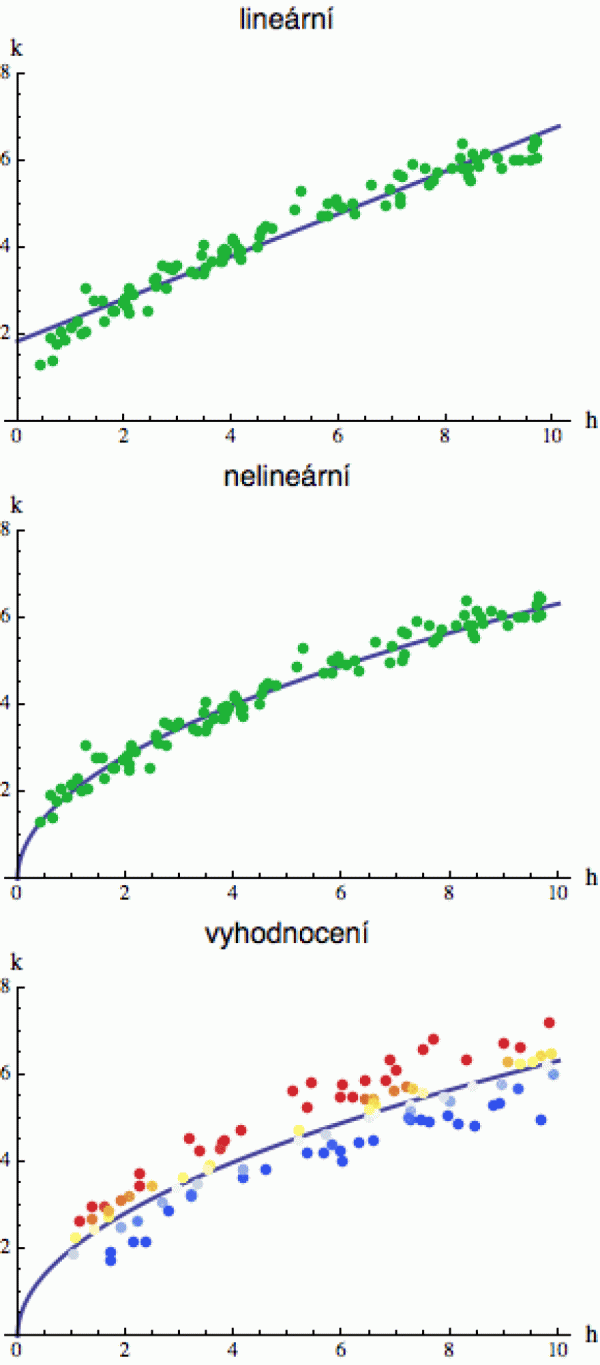
Představme si, že pracujeme v jabloňovém sadu a vyhodnocujeme produktivitu trhačů. Každý pracuje h hodin (osa x) a za tuto dobu natrhá k košíků jablek (osa y). Jejich výsledky vidíte na obrázku vpravo. Každý zelený bod reprezentuje jednoho trhače (někteří pracují jen chvilku a někteří takřka celý den).
Samozřejmě nám nic nebrání nasadit lineární regresi a najít přímku, která daná data nejlépe aproximuje, ale z vrchního obrázku vidíte, že zatímco uprostřed je většina bodů nad přímkou, na okrajích je většina pod ní a to často indikuje, že hledaná závislost nebude tak úplně lineární, jak si myslíme.
Jaký typ nelinearity pro popis zvolit, je nejtěžší část problému a do značné míry závisí na zkušenosti analytika. Obvykle se snažíme vyjít z nějaké množiny funkcí, která obsahuje několik volitelných parametrů, a ty potom ladíme pomocí nelineární regrese - opět se snažíme minimalizovat součet čtverců vzniklých reziduí. Tady už jsou ale algoritmy podstatně komplikovanější než u lineárního případu a parametry za vás obvykle najde nějaký software (u přímky si je můžete spočítat sami - jak za chvíli uvidíme).
V tomto konkrétním případě budu hledat aproximující funkci ve tvaru násobku obecné mocniny y = a * x^b (mimochodem, když si vezmete logaritmus obou stran, zjistíte, že je to vlastně lineární regrese v logaritmických souřadnicích). Nalezené optimum (parametry: a = 2, b = 0.5) vidíte na prostředním obrázku vpravo.
K čemu je taková funkce dobrá? Například k vyhodnocení nejúčinnějších sběračů. Já vím - mohli byste sběrače prostě oznámkovat podle celkového počtu košíků, ale asi cítíte, že to není úplně spravedlivé vůči těm, kdo se zdrželi jen pár hodin. Ti toho sice nenasbírali tolik, jako kdyby makali celý den, ale klidně mohli být produktivnější. Chceme-li ohodnotit efektivitu, musíme na to jinak.
Regresní křivka nám ukazuje, kolik košíků by měl v průměru nasbírat trhač pracující h hodin. Pro každého tedy poměříme jeho konkrétní počet košíků k s počtem k° předpovězeným regresní křivkou a jejich rozdíl nám dá výsledné hodnocení (spodní část obrázku). Lidově řečeno: ti, kdo jsou nad regresní křivkou, jsou šikulkové (v červeném), zatímco ti pod ní (v modrém) by se měli polepšit.
Zdroje nelinearity mohou být rozličné. V tomto případě je důvodem únava. Natrháte-li za první hodinu k košíků, neznamená to, že po 5 hodinách jich budete mít 5k. Člověk není robot. Podobnou křivku byste dostali, kdybyste si vynesli světové rekordy v běhu na X metrů. Zaběhnete-li stovku za 10 vteřin, neznamená to, že kilometr zaběhnete za 100 vteřin. Už na čtyřstovce uvidíte, že křivka trochu „uvadá“.
(zbytek této sekce můžete přeskočit)
Máte-li nezávislých proměnných několik, budete se muset seznámit s mnohonásobnou regresí, která je více dimenzionální verzí té jednoduché. K dispozici budeme mít m datových sad (bodů) obsahujících n + 1 čísel (x1, x2, ..., xn, y) a zajímat nás bude vztah mezi y a všemi těmi xn. Opět se pokusíme minimalizovat celkovou chybu, které se dopustíme, pokud empirické hodnoty y z datového souboru nahradíme hodnotami y° získanými z pravé strany následující rovnice.
y = a0 + a1 * x1 + a2 * x2 + ... + an * xn
(pozor, tady má index n trochu jiný význam než v teoretické sekci - tam nám označkoval jednotlivá měření jedné veličiny x, zatímco zde značí n-tou komponentu jednoho více-složkového měření)
Stejně jako u jednoduché regrese se pokoušíme aproximovat hodnotu y vhodnou lineární kombinací naměřených (či zjištěných) hodnot xn. Výsledkem tohoto procesu nebude přímka, ale nadrovina popisující nejpravděpodobnější vztah mezi y a x1, ..., xn. Získané koeficienty an pak udávají, jaký je vliv n-té nezávislé proměnné xn na odhadovanou hodnotu y (jsou to de facto vícedimenzionální ekvivalenty směrnice - jinak též normála příslušné nadroviny). Protože většina reálných problémů závisí na více proměnných, multiregrese představuje základ tradičně používaných statistických modelů.
Klasickým multiregresním problémem, který se dá považovat za zlatý standard internetových příruček, je problém odhadnutí ceny Bostonských domků (y) na základě 13 nezávislých proměnných (x1, ...x13), kterými jsou mimo jiné míra kriminality, výška daní z nemovitostí, koncentrace kysličníku dusičného, počet místností na dům, poměr žáků a učitelů v dané lokalitě a pár dalších. Data jsou veřejně dostupná (celkem 506 sad) a kuchařku k tomuto problému v jazyce Python naleznete zde.
U multidimenzionální regrese se někdy stane, že spočítané parametry a0, a1… an vyjdou „divoce“ (jsou to příliš velká čísla, která způsobují, že modely pak předpovídají hodnoty ode zdi ke zdi). V takových případech se při hledání optima současně minimalizuje souhrnná velikost těchto parametrů. Tomuto postupu se obecně říká regularizace) a v kontextu regrese se k nejznámějším regularizačním algoritmům řadí buď tzv. „Lasso regression“ anebo „Ridge regression“ (liší se od sebe tím, jak definujete „velikost“ parametrického vektoru).
Korelace
Zatím jsme se bavili převážně o tom, jak regresní přímku (či křivku nebo nadrovinu) najít. Jakmile ji máme, můžeme z vybraných hodnot x začít předpovídat hodnoty y. Jak bude předpověď kvalitní, závisí na tom, jak těsně se původní data k regresní přímce přimykají. Kvantitě, která úspěšnost aproximace měří, se říká korelace (hodnot x a y).
Na dalším obrázku jsou dva soubory dat, jejichž regresní přímka je v podstatě stejná (zhruba y = 1 + x/2). To v čem se datové soubory liší, je „rozptyl“ bodů podél regresní přímky. Body vlevo se od ní odchylují podstatně méně, což znamená, že náhodné proměnné x a y mají v tomto případě lepší korelaci.
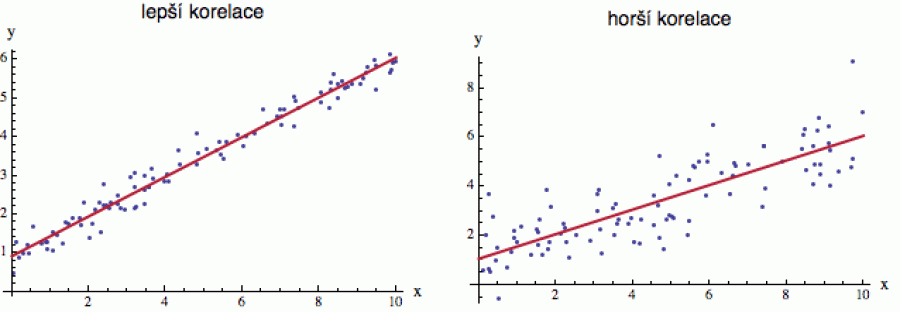
Korelace dvou náhodných proměnných tedy ukazuje, do jaké míry se změny
jedné z veličin dají odvodit ze změn té druhé - zda obě rostou či
klesají tak říkajíc ruku v ruce, anebo zda jsou jejich změny víceméně
nezávislé.
Protože míra korelace nás často zajímá víc než typ regresní závislosti, existuje pro ni explicitní vzoreček, který nemusíte ždímat z regresního softvéru.
Mějme tedy dvě náhodné proměnné X a Y, realizované jako n bodů:
data = (x1, y1), (x2, y2), (x3, y3), ... (xn, yn)
Korelace mezi X a Y v tomto vzorku pak bude:
r = (Σ (xi - mx) * (yi - my)) / ((n-1) * sx * sy)
kde mx a my jsou průměry hodnot xi a yi, zatímco sx a sy jsou jejich směrodatné odchylky (sigma opět značí sumu přes všechny hodnoty i).
Číslo r leží mezi -1 a 1 a říká se mu Pearsonův korelační koeficient. Pokud je kladný, pak nárůst x odpovídá nárůstu y. Je-li záporný, tak se y s rostoucím x naopak zmenšuje (statisticky vzato). Čím je toto číslo v absolutní hodnotě blíž jedničce, tím je synchronizace mezi pohybem x a y přesnější. Abyste to dostali „do ruky“, můžete se podívat na tabulku několika datových souborů s vyznačenou korelací (na prostředním řádku vidíte, že korelace je „slepá“ k typu závislosti, tedy k tomu jak rychle regresní přímka roste - zajímá ji pouze, jak moc se od ní data odchylují).
Podívejme se na malý příklad (pět hodnot pro každou proměnnou)
X = (1, 2, 3, 2, 1)
Y = (3, 5, 7, 5, 3)
Koeficient korelace mezi X a Y bude v tomto případě jednička (perfektní skóre)
r(X, Y) = 1
protože oba soubory rostou nebo klesají synchronizovaně. Zda Y roste dvakrát nebo třikrát rychleji než X, je vcelku jedno (zkuste si třeba Y = (2, 5, 8, 5, 2), pořád jednička). To odpovídá předchozí poznámce o „slepé“ korelaci - když si body (X, Y) vynesete do grafu, uvidíte přesnou přímku. Pokud ale změníte Y na (3, 5, 7, 5, 2) dostanete r(X, Y) = 0.981. Korelace bude trochu menší, protože růst X a Y už nejde přesně ruku v ruce.
Protože ve většině případů nás zajímá jen, jak je vztah silný (a ne zda se obě proměnné pohybují souběžně či protiběžně), často se jako hodnota korelace uvádí r2 (er kvadrát), což je pak číslo mezi 0 (žádná závislost) a 1 (perfektní závislost). Pro ilustraci: na úvodním obrázku má „lepší korelace“ hodnotu r2 = 0.97 a ta „horší“ r2 = 0.69.
Závěrem této podsekce malý detail. Zatímco u regrese zhusta platí, že hodnota X je nezávisle volená a hodnota Y pak na ní nějakým způsobem závisí, korelační koeficient nám pouze ukazuje míru souvztažnosti obou proměnných a obecně se z něho nedá odvodit žádná kauzalita (příčinnost). Vezměme si třeba počet zasahujících hasičů při požáru versus vyčíslená škoda. Mezi těmito dvěma veličinami bude pravděpodobně velmi solidní korelace, ale z ní nemůžeme usoudit, že vyšší počet hasičů způsobuje vyšší škodu. To by nám hasiči dali! Korelace v tomto případě znamená, že obě proměnné prostě závisí na intenzitě požáru.
Literární shrnutí: Nelítostné odpolední slunce bušilo všemi paprsky do kaktusových plání obklopujících arizonské městečko Silver Creek. Uprostřed zaprášené ulice stál Krvavý Džejk v plátěné košili a ocelovým pohledem si přeměřoval neznámého desperáta pomalu se sunoucího směrem k němu. Ve vzdálenosti 50 stop se nedbale oblečený kovboj zastavil. Oba muži počali zlověstně mhouřit oči, jako by se pokoušeli překonat letitý rekord Charlese Bronsona. Na stříšce saloonu „U bídného kojota“ seděli dva supi a s nelíčeným profesionálním zájmem scénku pozorovali. „Vaše kalkulačky visí proklatě nízko, cizinče,“ zahájil konverzaci Džejk. Neznámý muž mlčel a soustředěně žvýkal hrudku tabáku. Džejk zúžil štěrbinu mezi víčky tak, že by jí neprolétlo ani zrnko písku ze Sonorské pouště. „Zjistil jsem, že existuje pozoruhodná korelace mezi počtem ztracených koní a délkami vašich návštěv v našem městečku," procedil mezi zuby. Cizincovy ruce se instinktivně přiblížily ke dvěma výpočetním strojům zavěšeným v koženém pouzdře u pasu: „Soudím, že ta korelace nebude víc než 0.3.“ I Džejk spustil ruce ke dvěma ohmataným kalkulačkám značky Casio a jeho prsty se začaly ve vzduchu nedočkavě komíhat. Desperát tasil jako první a oba muži se pustili do horečného počítání. „Mám to!“ vyrazil vítězoslavně Džejk. „R kvadrát je 0.96!“ A s těmito slovy vytáhl z náprsní kapsy revolver a naládoval do zkoprnělého padoucha takové množství olova, že by si z něj zručná myš lehce vyrobila radiační izolaci v atomovém bunkru. Džejk byl tvrdý chlap - vždy nejprve střílel a teprve pak si kladl otázku, zda korelace implikuje příčinu. Supům na stříšce to bylo srdečně jedno.
Sekce jauvajs: Metoda nejmenších čtverců
jen pro otrlé povahy
Jak si tedy lze tu regresní přímku spočítat přímo z dat?
Nejprve si označíme n bodů
data = (x1, y1), (x2, y2), ... (xn, yn)
a přímku budeme hledat ve směrnicovém tvaru y = a + bx.
Výše jsme si řekli, že chceme minimalizovat celkovou odchylku o:
o(a, b) = Σ (yi - yi°)2 =
Σ (yi - a – b * xi)2
kde yi° je bod na hledané přímce odpovídající hodnotě xi (tj. yi° = a + b * xi).
U odchylky o jsem tentokrát explicitně vyznačil, že závisí na dvou neznámých číslech a, b (průsečík a směrnice). Vše ostatní ve vzorečku jsou konkretní zadaná čísla. Na odchylku se tedy můžeme dívat jako na funkci dvou proměnných a o nich je známo, že většinou nabývají extrému tam, kde je derivace podle obou proměnných rovná nule (zhruba platí, že tam kde má funkce extrém, je tečna ke grafu funkce rovnoběžná s osou x - a funkce tam tedy má nulovou derivaci). Jen budeme muset derivovat parciálně (není to nic těžkého, prostě se na tu druhou proměnnou budeme vždy dívat jako na konstantu). To, co nám vyjde, položíme rovno 0:
∂o/∂a = -2 Σ (yi - a – b * xi) = 0
∂o/∂b = -2xi Σ (yi - a – b * xi) = 0
(to smetí před Σ pochází z derivace vnitřní funkce podle
příslušné proměnné)
Tohle vypadá na první pohled děsivě, ale protože všechna čísla xi a yi jsou známá, formulky nejsou nic jiného než dvě lineární rovnice pro dvě neznámé a a b. Ty vyřešíme (trochu se u toho zapotíme) a vyjdou nám explicitní vztahy pro a a b:
b = (n Σxi * yi - Σxi Σyi) / (n Σxi2 - (Σxi)2)
a = (Σyi – b * Σxi) / n
a na pravé straně máme už jen různé kombinace zadaných dat.
Na regresi se ale můžeme dívat také rovnicově (tedy prostřednictvím lineární algebry). Hledáme přímku y = a + bx a máme n bodů, kterými by měla procházet. To vede k tzv. přeurčené soustavě n rovnic pro dvě neznámé, která obvykle nemá řešení (nic překvapivého - těch n bodů se obecně proložit přímkou nedá).
a + b * x1 = y1
a + b * x2 = y2
...
a + b * xn = yn
V takovém případě se musí najít přibližné řešení tak, že se vektor pravých stran promítne do roviny určené sloupci matice odpovídající levé straně. Korelace pak má hezký geometrický význam - je to kosinus úhlu mezi vektorem pravé strany a zmíněnou rovinou. K tomuto přístupu se časem vrátím. Chcete-li se v tom začít nimrat hned, mrkněte se sem.
Článek je redakčně upravenou verzí blogového příspěvku na serveru
iDNES.cz. Publikováno s laskavým svolením autora.
Další díly a původní texty jsou dostupné na blogu Jana Řeháčka.
{kind=link}