
Jak naučit umělou inteligenci co nejlépe rozeznávat klíčová slova v textu? Na tento problém se ve své bakalářské práci zaměřil Adam Osuský. Výsledkem je nejen nová metoda, která může pomoci výzkumníkům i specialistům v praxi, ale také nové příležitosti, které se Adamovi otevřely.
Mohl byste stručně představit svou práci?
Moja bakalárska práca sa zaoberá predikciou dôležitosti slov v texte, od definovania konceptu až po vytvorenie a vyhodnotenie predikčného systému.
Prvou časťou práce bolo vytvorenie datasetu pre daný problém, konkrétne nájdenie správneho spôsobu získavania anotácií dôležitosti slov od ľudí. Bolo potrebné sa zamyslieť nad tým, ako túto dôležitosť reprezentovať a čo vlastne dôležitosť slova znamená.
Druhou časťou bolo natrénovanie umelej inteligencie. Trénovacie dáta sme generovali automaticky: zobrali sme existujúci text a doň sme umelo vložili nadbytočné slová. Následne sme trénovali model, aby sa naučil identifikovať tieto umelo vložené slová. Intuícia za tým bola, že výsledný model bude priraďovať vyššiu pravdepodobnosť vloženia menej dôležitým slovám.
V video ukážke môžeme vidieť, ako umelá inteligencia najskôr označí 10% najdôležitejších slov, zoradených od najvýznamnejšieho po najmenej dôležité. Následne je pre porovnanie zobrazené, ako ľudia zoradili tie najpodstatnejšie slová.
Co vás inspirovalo k tomu, abyste se zaměřil právě na toto téma?
Mal som zapísaný predmet “Soutěžní strojový překlad” pod vedením pána profesora Ondřeja Bojara. Ide o výborný predmet vo forme workshopu. Na začiatku semestra sú predstavené potenciálne témy na projekty, z ktorých si študenti môžu vybrať a začať na nich pracovať. Projekty sú zamerané predovšetkým na oblasť spracovania prirodzeného jazyka (Natural Language Processing).
Jednu z týchto tém navrhol Dávid Javorský, doktorand profesora Bojara. Téma sa týkala relatívne kratšieho experimentu trénovania modelu na umelo vložených slovách a následnej analýzy vlastností modelu.
Túto tému som si vybral a na konci semestra sme dosiahli zaujímavé výsledky, ktoré nás motivovali venovať sa tejto problematike hlbšie. Nakoniec sa z toho stal začiatok mojej bakalárskej práce, ktorú viedol Dávid Javorský.
Můžete vysvětlit, jaký konkrétní přínos nebo využití má vaše práce?
Prvým prínosom tejto práce je náš prístup k formalizácii pohľadu na dôležitosť slov a metodológia, ktorú sme vyvinuli na zbieranie anotácií. Tento prístup môže slúžiť ako základ pre ďalších výskumníkov, ktorí sa zaoberajú štúdiom dôležitosti slov.
Druhým prínosom je samotný dataset, ktorý môže slúžiť na evaluáciu iných modelov zameraných na predikciu dôležitosti slov. Taktiež môže byť využitý lingvistami, ktorí skumajú vlastnosti dôležitých slov.
Tretím prínosom je nová metóda trénovania modelu, ktorá umožňuje automatické generovanie trénovacích dát.
Všetky tieto výsledky môžu byť využité pri riešení rôznych úloh v oblasti spracovania prirodzeného jazyka, ako sú extrakcia kľúčových slov, sumarizácia textov alebo zlepšovanie chatbotov pracujúcich s viacerými dokumentmi.
S jakými technologiemi jste pracoval a jaké metody jste využíval?
Z teoretického hľadiska ide o oblasť strojového učenia, konkrétne deep learning, ktorý využíva umelé neurónové siete. Z praktického hľadiska bol celý kód napísaný v Pythone, ktorý je v súčasnosti pravdepodobne najpopulárnejšou voľbou v oblasti strojového učenia. Na trénovanie modelov sme použili pomocné frameworky PyTorch a HuggingFace Transformers. Výber týchto nástrojov bol odôvodnený ich aktuálnou popularitou a rozsiahlou dokumentáciou. Výpočtové zdroje poskytol projekt e-INFRA CZ MetaCentrum, podporovaný Ministerstvom školství, mládeže a tělovýchovy České republiky.
Co bylo během psaní vaší práce nejtěžší? Dostal jste se někdy do slepé uličky? Je něco, co byste zpětně udělal jinak?
Keďže táto práca mala skôr výskumný charakter, počas každého kroku sme postupne narážali na rôzne slepé uličky. Celý proces bol iteratívny. Pri zbere anotácií sme museli prejsť niekoľkými cyklami, kým sme našli správny spôsob. Pri robení experimentov v strojovom učení je bežnou praxou opakovane spúšťať experimenty, analyzovať priebežné výsledky, spraviť vylepšenia a spustiť ich znova.
Jedna vec, ktorú by som spätne urobil inak, je dôsledné zaznamenávanie každej iterácie a každého rozhodnutia do poznámok. Pri písaní záverečného textu by som takéto poznámky veľmi ocenil.
Jakým způsobem jste ověřoval výsledky své práce?
Súčasťou tejto práce bolo zbieranie anotácií dôležitosti slov. Na tento účel bola vytvorená jednoduchá webová aplikácia, v ktorej bol anotátor vystavený krátkemu textu o dĺžke približne 50 slov. Anotátor mal následne možnosť označiť poradie top 10 % najdôležitejších slov podľa svojho názoru.

Dôležitou súčasťou tohto procesu bolo správne formulovanie inštrukcií pre anotátorov a jasné vysvetlenie pojmu "dôležitosť slov". My sme sa zamerali na sémantickú dôležitosť a v bakalárke sme diskutovali o rôznych faktoroch, ktoré ju môžu ovplyvniť.
Z analýzy nazbieraných dát sme získali niekoľko zaujímavých pozorovaní. Každý text bol anotovaný viacerými ľuďmi. Anotovali sa texty z rôznych domén. Najvyššiu mieru zhody sme zaznamenali pri textoch z domény vtipov, zatiaľ čo najnižšiu pri poézii, čo je celkom intuitívne a očakávané.
Bolo potrebné navrhnúť špeciálne metriky na porovnanie miery zhody medzi dvoma rôznymi anotáciami. Ukázalo sa, že nie je jednoduché porovnať dve poradia, ktoré môžu obsahovať odlišné položky. Navrhli sme tri metriky, pričom každá z nich predstavovala vylepšenie tej predchádzajúcej. A nakoniec sme sa rozhodli pre average overlap (AO) metriku.
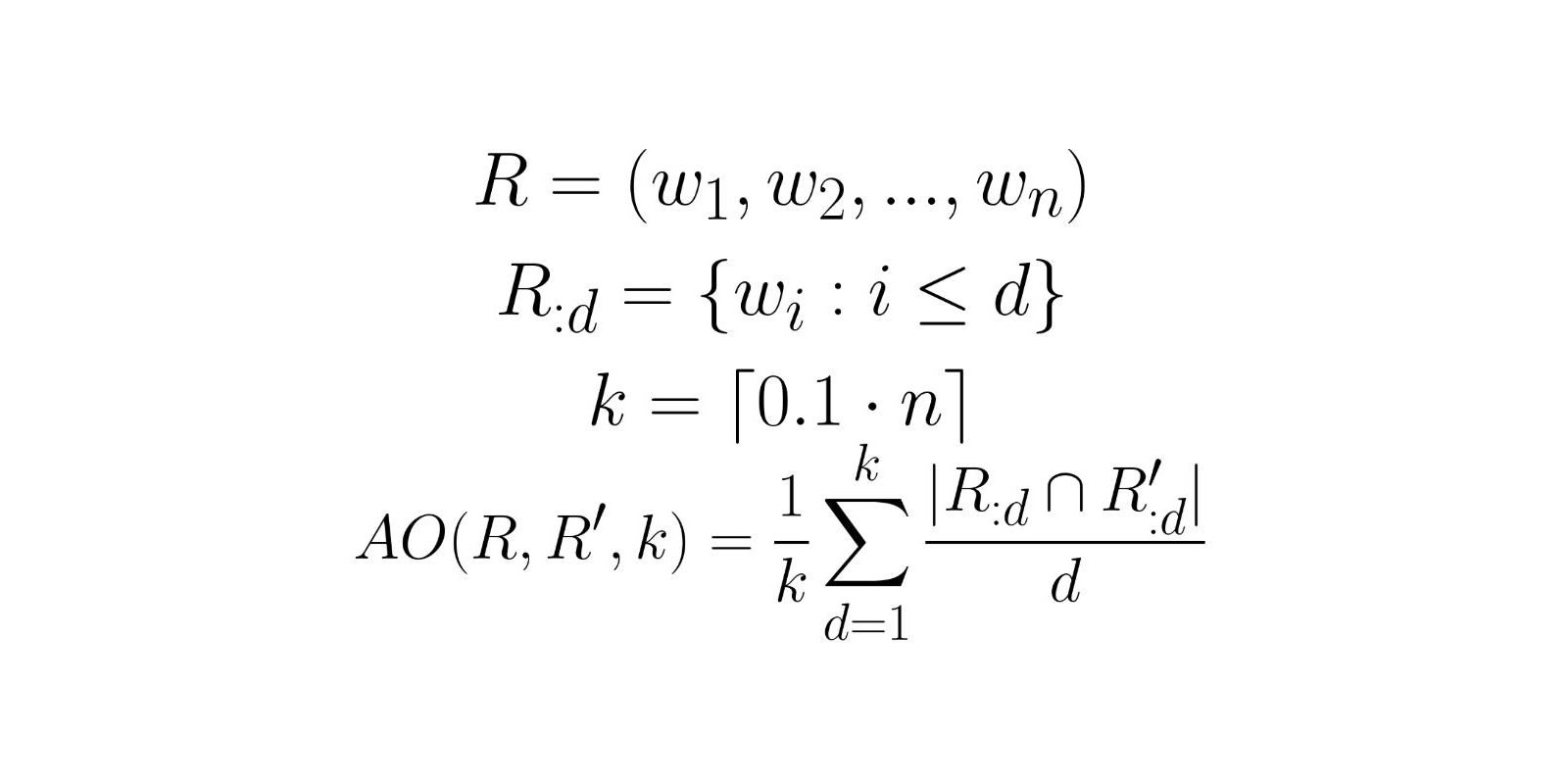
Nazbierané anotácie sme následne spriemerovali a použili ich na evaluáciu našich natrénovaných modelov.

Co považujete za nejdůležitější výsledek nebo závěr své práce?
Naše natrénované modely sme porovnali na nami vytvorenom datasete s rôznymi inými metódami. Porovnávali sme ich s klasickou štandardnou metódou TF-IDF, ktorá existuje už roky a je stále často používaná. Ďalej sme zahrnuli moderný prístup (PI, NLI), ktorý vyvinul môj vedúci, Dávid Javorský. Nakoniec sme ako hornú hranicu použili mieru zhody medzi našimi anotátormi.
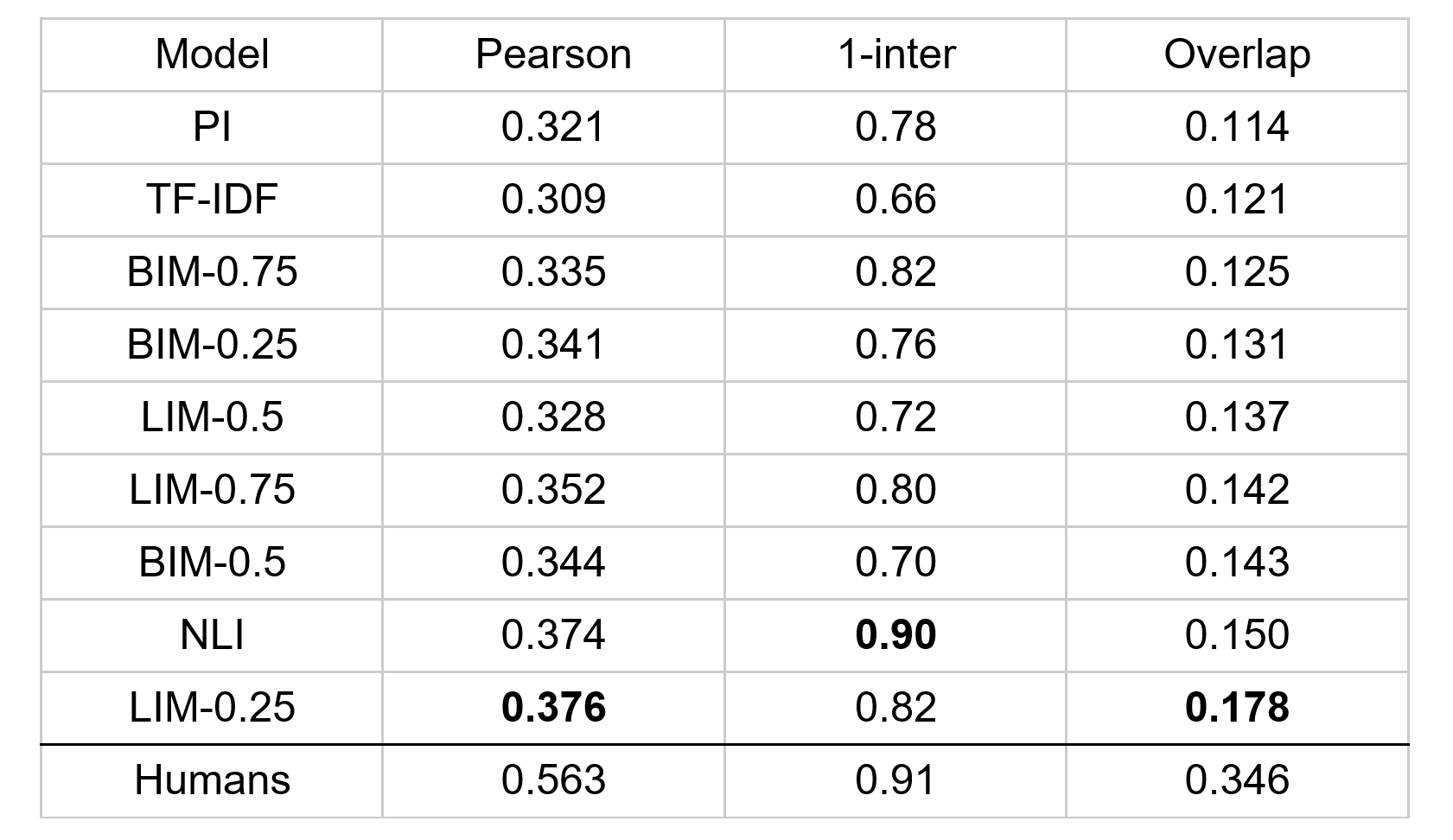
Z našich výsledkov vyplýva, že naše modely prekonali tradičnú metódu TF-IDF a sú konkurencieschopné voči modernému prístupu. Náš najlepší model dokonca prekonal spomenutý moderný prístup. Avšak výkon nášho najlepšieho modelu dosiahol len približne polovicu hodnoty evaluovanej metriky v porovnaní so zhodou medzi anotátormi. To naznačuje, že je stále priestor na zlepšenie a približovanie sa k ľudskej úrovni presnosti.
Máte pocit, že vaše práce může být inspirací pro další studenty nebo odborníky v dané oblasti?
Na bakalárskej práci som tvrdo pracoval a snažil som sa na maximum, preto budem veľmi rád, ak výsledky tejto práce prispejú k ďalšiemu vývoju a výskumu v oblasti dôležitosti slov. Dokonca sa nám podarilo na základe tejto práce napísať článok, ktorý už je publikovaný na workshop-e Information Technologies – Applications and Theory 2024. Na tomto workshop-e prejavili výskumníci lingvistiky záujem o naše nazbierané dáta, čiže je možné, že im to pomôže v ich výskume.
Verím, že tento projekt môže inšpirovať ďalších študentov, aby sa nebáli zbierať vlastné dáta, na ktorých môžu testovať svoje modely. Už len samotná analýza nazbieraných dát môže priniesť zaujímavé poznatky, a vytvorený dataset môže výrazne pomôcť komunite zaoberajúcej sa rovnakou problematikou.
Jaké jsou vaše plány do budoucna?
Zručnosti a skúsenosti získané počas práce na bakalárke mi pomohli získať moju prvú odbornú stáž v AI startupe Rossum. Táto firma sa zameriava na inteligentné spracovanie transakčných dokumentov, ako sú napríklad faktúry. Počas stáže som pracoval na výskumnom projekte, ktorý experimentoval s podobnými myšlienkami ako moja bakalárka. Nášmu tímu sa na tomto projekte dokonca podarilo vylepšiť umelú inteligenciu, ktorá sa používala na produkcii.
V súčasnosti pracujem v AI startupe knowdroids.ai, kde vyvíjame autonómnych AI agentov, ktorí pracujú s veľkým množstvom interných dokumentov. Pri extrakcii informácií z týchto dokumentov je pre našich agentov užitočné identifikovať dôležité časti textu. Čiže aj tu sa teda naďalej venujem podobným problémom ako moja baklárka.
Musím sa srdečne poďakovať Matfyzu a všetkým mojím učiteľom. Dobre ma pripravili na budúcnosť a dali mi veľmi kvalitný základ, na ktorom sa mi už ľahko budú stavať nové zručnosti a poznatky. „Jednou matfyzák, navždy matfyzák.“
Repozitář
UK
Github
Článek ITAT
Lindat
Osobní stránky Adama
Osuského



