Neuronové sítě zažívají v poslední době velký rozmach. K oblastem, kde v současnosti nacházejí uplatnění, patří i zpracování obrazu pro strojové vidění a následné hodnocení kvality průmyslových výrobků.
Teoretické základy hlubokého učení, resp. neuronových sítí položil v 60. letech americký vědec a profesor na Stanfordově univerzitě Bernard Widrow. Představil tehdy další zobecnění základního neuronu a tzv. adaptivní lineární element. Zasloužil se také o zobecnění na reálné vstupní hodnoty a představil nové učicí pravidlo neuronu.
V roce 1969 však došlo v oblasti vývoje ke krizi. Marvin Lee Minsky, vědec z americké MIT a významná postava v oblasti umělé inteligence, poněkud účelově zpochybnil koncept umělých neuronových sítí. Využil k tomu tzv. XOR problém (logická funkce „výhradní nebo“). Minsky tvrdil, že jednovrstvá neuronová síť není schopna logickou funkci XOR vyčíslit. Konstatoval, že řešením je použití více vrstev a chybně předpokládal, že učicí algoritmus nebude možné vzhledem ke komplikovanosti struktury sítě nalézt. Jeho závěry měly za následek přesměrování finančních prostředků do jiných oblastí umělé inteligence a dočasné zbrždění vývoje v oblasti umělých neuronových sítí.
Teprve v roce 1986 odvodila skupina badatelů algoritmus, kterým lze vícevrstvé sítě učit na principu zpětného šíření chyby. S nástupem výkonných počítačů se tak rozběhlo vědecké bádání v této oblasti a postupné zavádění výsledků do praxe.
Využití neuronových sítí při kontrole kvality výrobků
Pro kvalitativní hodnocení výrobků v průmyslových aplikacích je velmi důležité využívat takové metody, které přinesou dobré výsledky, budou dostatečně výkonné a také rychlé. Tyto požadavky začínají splňovat právě metody využívající hluboké učení, které jsou při vhodném použití schopny překonávat dosavadní klasické přístupy.
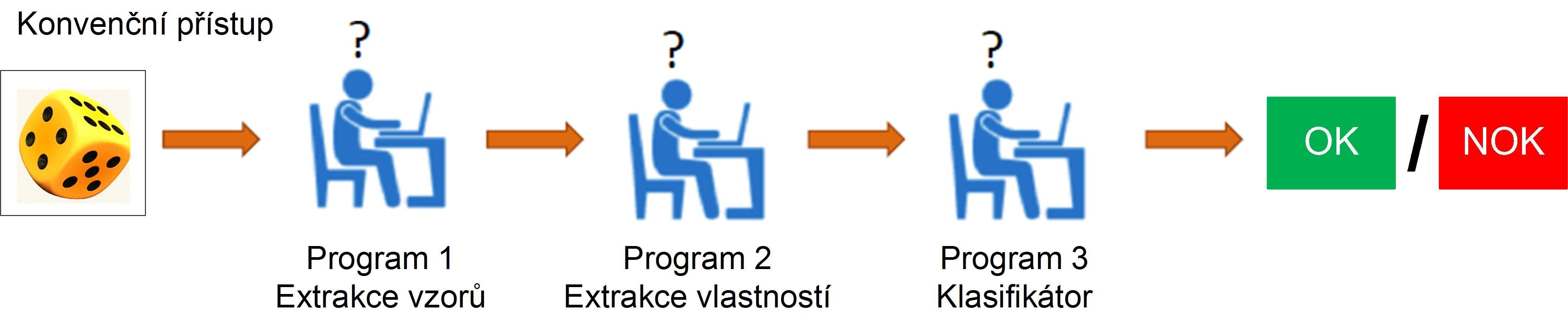
Při „konvenčním přístupu“ (obr. 1) jsou vstupní data podrobována postupně krokům, které vyhodnocují nasnímaný obraz, musí nalézt požadované zkoumané vlastnosti a ty potom podrobit klasifikaci. Výsledkem je pak rozdělení vstupního obrazu klasifikací na dobrý výrobek (OK), nebo výrobek s vadou (NOK – not OK). Velmi často je při změně výrobku, výrobního postupu nebo změně scény nutné provést nové nastavení celého řetězce programového řešení.
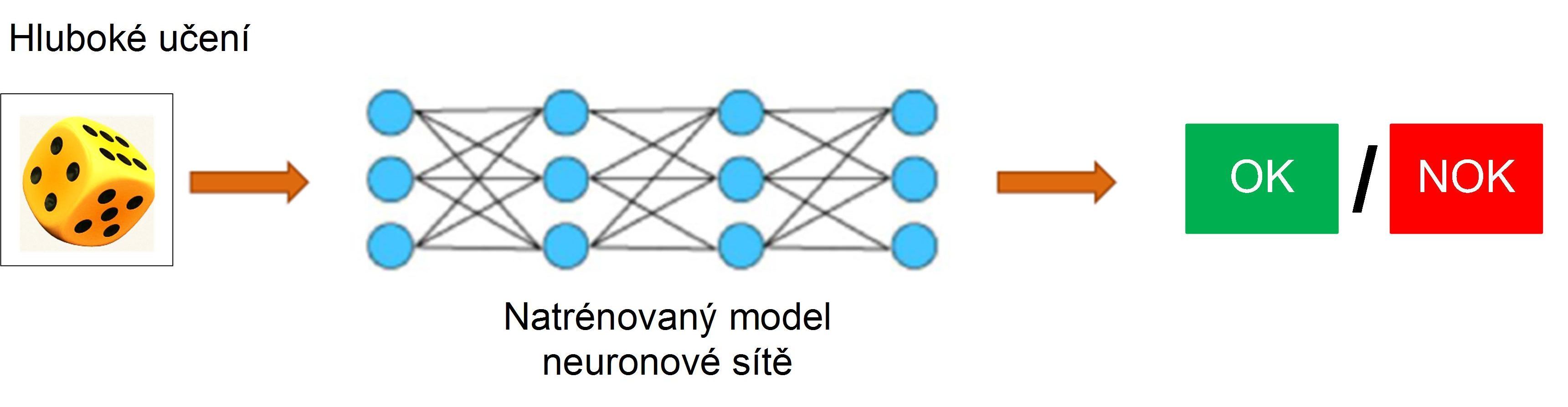
Ze zkušeností lze usuzovat, že konvenční metody inspekce ve strojovém vidění nemohou smysluplně analyzovat nepravidelné snímky, kde defekty nejsou přesně definovány. Naproti tomu aplikování metod hlubokého učení umožňuje přístup obecnější (obr. 2). Neuronovou síť je však třeba dobře vytrénovat, což samozřejmě vyžaduje čas a mnohem větší objem přípravné práce.
Jak „vycvičit“ stroj
Programový systém hlubokého učení musí nejprve projít fází učení, tedy tréninkem, při kterém se naučí rozpoznávat změnu ve struktuře, tedy vadu na hodnocených výrobcích. Na obr. 3 je příklad určitého výrobku, který je třeba hodnotit s ohledem na výskyt případné vady ve struktuře. Aplikování konvenční metody by bylo poměrně náročné, zejména z důvodu upřesnění rozhodovací podmínky, co je a co není vada.

Algoritmus hlubokého učení podrobíme fázi tréninku s tím, že mu „ukážeme“ výrobky bez vady a s vadou (obr. 4). Při dostatečném počtu vzorků se neuronová síť naučí rozeznávat takové změny ve struktuře, které klasifikujeme OK, resp. NOK. Zmíněný „dostatečný počet vzorků“ je omezen jednak časem, který máme na trénovací fázi, a jednak mohutností systému, především jeho pamětí.

Obecný postup řešení úlohy strojového vidění pomocí hlubokého učení lze popsat například takto:
1. Získání sady obrázků
2. Označení obrázků (labelling) – např. OK / NOK
3. Rozdělení sady obrázků na trénovací sadu a testovací sadu
4. Naučení modelu na trénovací sadě obrázků
5. Otestování modelu vyhodnocením obrázků z testovací sady
6. Ověření přesnosti modelu

7. Pro VYHOVUJÍCÍ (vada byla detekována) – integrace modelu do funkční
aplikace
Pro NEVYHOVUJÍCÍ (vada byla označena, ale nedetekována) – rozšíření
sady obrázků a opakování postupu
8. Celý postup lze vícekrát iterativně opakovat
Předchozí díly:
Strojové
zpracování obrazu: Využití neuronových sítí I
Strojové
zpracování obrazu: Klíč k Průmyslu 4.0?
Strojové
zpracování obrazu: Obrazová fúze
Strojové
zpracování obrazu: Fuzzy logika v praxi
Strojové
zpracování obrazu: Fuzzy logika