
Jak se vypořádat s exponenciálním nárůstem genetických dat, která narážejí na limity paměti současného hardwaru? Ondřej Sladký ve své bakalářské práci představil „maskované nadřetězce“, inovativní metodu reprezentace k‑merových množin, která vyniká výrazně lepší kompresibilitou než dosud používané přístupy. Teoretický základ, který Ondřej implementoval v efektivním kódu v C++, stihl vzbudit ohlas na mezinárodních konferencích ještě před obhájením práce a brzy nato vyšel i v prestižním časopise Bioinformatics Advances. Práce vyhrála cenu děkana a první místo ve SVOČ.

Ondřej se nedávno na pár dnů zastavil v Praze a vy si teď můžete přečíst, jak se studentovi Matfyzu podařilo propojit informatickou teorii s praxí špičkové bioinformatiky a proč jeho řešení pomáhá k relevantnějším výsledkům při analýze genomů lidstva i virů.
Mohl byste stručně představit svou práci?
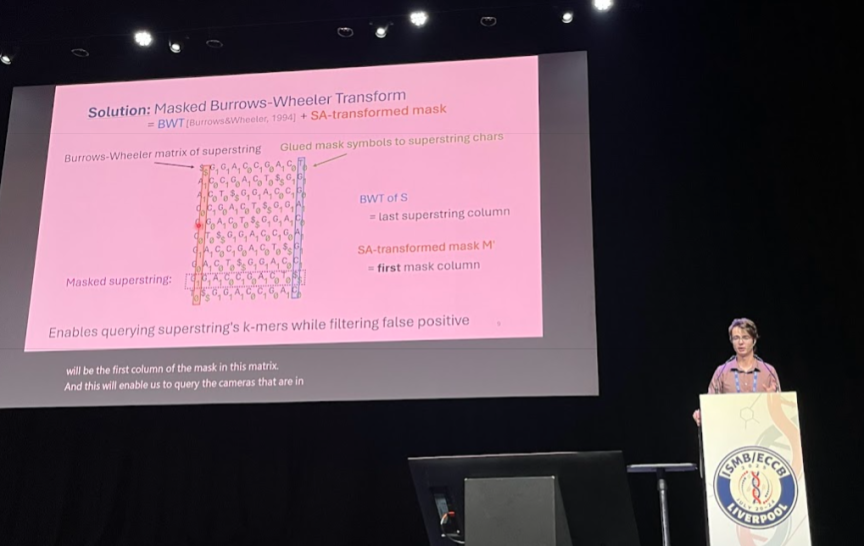
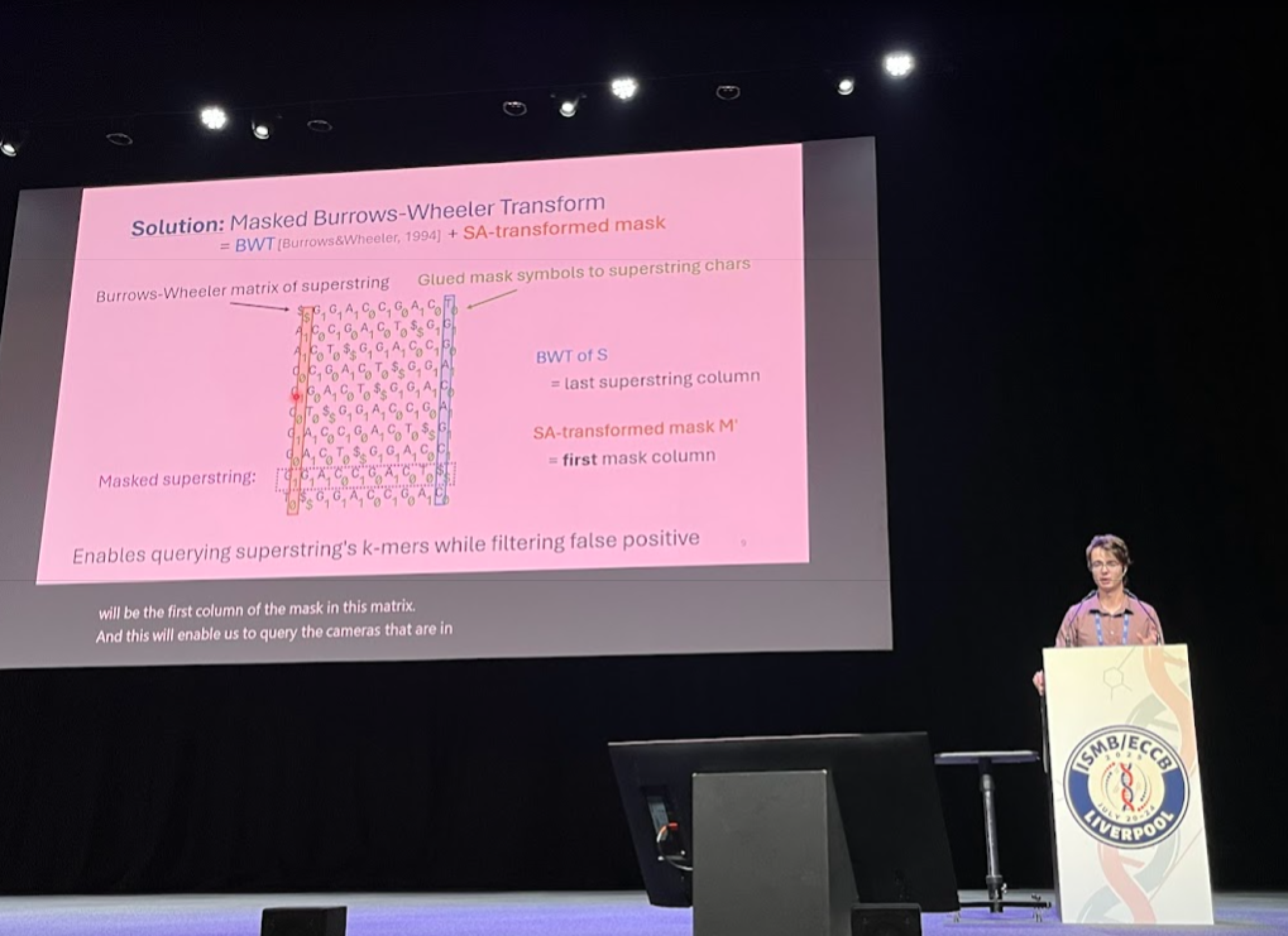
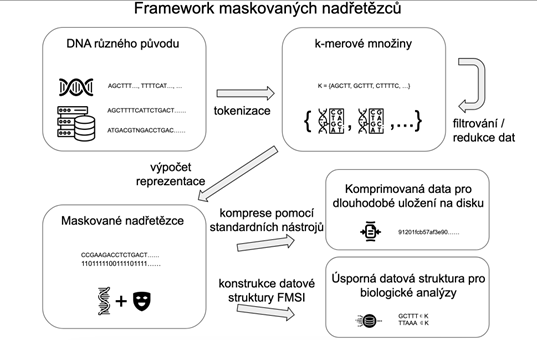
Jednou z velkých výzev současné bioinformatiky je, jakým způsobem se vypořádat s exponenciálním nárůstem genetických dat v databázích. Technikou, která se čím dál častěji používá k částečnému řešení tohoto problému, je reprezentovat genetická data pomocí množin k‑merů, tedy všech podřetězců délky k z nějakého řetězce DNA, který může pocházet z jednoho či více organismů nebo přímo z prostředí. A právě efektivní reprezentací množin k-merů se zabývá moje práce. Hlavním přínosem je nový a úspornější způsob reprezentace k-merových množin. Takzvané maskované nadřetězce (masked superstrings) sestávají z nadřetězce, tedy řetězce obsahujícího všechny k‑mery, a binární masky, která říká, jaké k‑mery jsou v nadřetězci skutečně obsaženy. Kromě toho se práce zabývá například tím, jak tyto maskované řetězce efektivně počítat, a také paměťově efektivními datovými strukturami založenými na maskovaných nadřetězcích.
 Framework maskovaných
nadřetězců
Framework maskovaných
nadřetězců
Co vás inspirovalo k tomu, abyste se zaměřil právě na maskované nadřetězce?
Nejspíše to byla kombinace zajímavého tématu z oblasti, které jsem předtím moc nerozuměl, takže jsem se mohl naučit něco nového, příležitosti pracovat na projektu, který by mohl mít i nějaký výzkumný dopad, možnosti spolupracovat s někým ze zahraničí a sympatického vedoucího, abych začal dělat na ročníkovém projektu na toto téma. Tím, že spolupráce s oběma, Pavlem Veselým a Karlem Břindou, pak fungovala velmi dobře a měli jsme spoustu souvisejících nápadů, tak se z toho docela přirozeně vyvinula i bakalářská práce.
Můžete vysvětlit, jaký konkrétní přínos má vaše práce?
Hlavní výhodou maskovaných nadřetězců oproti existujícím reprezentacím je jejich lepší kompresibilita, obzvláště pro takzvané subsamplované datasety, které jsou čím dál tím více používané. Také jsme na základě maskovaných nadřetězců vyvinuli datovou strukturu, která je konzistentně paměťově úspornější než existující přístupy. Tím, že pro spoustu biologických aplikací je paměť hlavní limitující faktor, tak to zjednodušeně znamená, že různé biologické analýzy by díky našemu přístupu mohly na stejném hardwaru se stejnou pamětí zanalyzovat více dat a tedy potenciálně dojít ke kvalitnějším a relevantnějším biologickým výsledkům.
S jakými technologiemi jste pracoval, jaké metody jste využíval, a proč zrovna tyto?
Nástroje na výpočty a indexování maskovaných nadřetězců jsem implementoval v C++, protože u softwaru, který pracuje s genomickými daty, je naprosto nutné, aby byl napsaný v nějakém vysoce efektivním jazyce. Jinak by ty nástroje byly příliš pomalé pro jakékoliv použití v praxi.
Co bylo během psaní vaší práce nejtěžší? Bylo něco, na čem jste se zasekl, nějaká cesta, co nikam nevedla?
Asi nejtěžším bodem pro mě bylo, když jsem náš první článek prezentoval na konferenci ještě předtím, než jsem začal psát samotnou bakalářku. Nikdy dřív by mě nenapadlo, že se dá přípravou prezentace strávit tolik času. Tím, že jsem do projektu vstupoval hlavně jako teoretický informatik, naprosto nepolíbený bioinformatikou, bylo pro mě dost náročné do oboru proniknout. Musel jsem dobře pochopit, jak přesně fungují práce, které dělají něco podobného jako my, a zjistit, jakým způsobem lidé v tomto oboru přemýšlejí a co považují za důležité, abych pak mohl zvolit vhodný způsob, jak výsledky prezentovat. Tato zkušenost mi nakonec velmi pomohla při psaní samotné bakalářské práce, protože už jsem věděl, co je důležité a jakým způsobem bych měl výsledky poskládat a prezentovat. Slepých uliček však bylo hodně, určitě budu mít desítky stránek s různými nápady, které se pak vůbec nikde nepoužily, protože příběhově nepasovaly mezi ostatní nebo se třeba ukázalo, že vlastně nejsou zas tak zajímavé.
Jakým způsobem jste ověřoval výsledky své práce?
Experimentální výsledky, tedy demonstrování toho, že náš framework je paměťově úspornější než dřívější přístupy, jsem měřil na vybraných genomech a kolekcích genomů. Ty pocházely z různých organismů z veřejných repozitářů, ať už šlo o lidský genom, nebo o kolekci všech nasekvenovaných genomů covidu.
Co považujete za nejdůležitější výsledek nebo závěr své práce?
Myslím, že ten klíčový výsledek je, že maskované nadřetězce, na rozdíl od jiných reprezentací množin k-merů, mají lepší kompresní vlastnosti konzistentně, tedy na rozdíl od předchozích způsobů fungují dobře nejen pro genomická data, u kterých platí různé strukturní předpoklady.
Máte pocit, že vaše práce může být inspirací pro další studenty nebo odborníky v dané oblasti?
Věřím, že určitě. Obzvlášť vzhledem k tomu, že se před maskovanými nadřetězci myslelo, že už je problém lepší reprezentace vyřešený a že to otevírá úplně nový prostor pro další výzkum. Na základě bakalářské práce už mj. vznikly tři odborné články, které jsem prezentoval na bioinformatických konferencích, a přišlo mi, že měly vždy dobré ohlasy – jeden z nich nedávno vyšel v časopise Bioinformatics Advances. Dále také bakalářský student Ján Plachý navazoval s mým vedoucím s lepšími algoritmy na výpočet maskovaných nadřetězců a také z jeho práce se rýsuje zajímavý článek.
Jaké jsou vaše plány do budoucna?
Po dopsání bakalářky jsem byl chvíli na stáži v Eligo Bioscience, kde jsem podobné techniky, hlavně co se implementace týče, používal k řešení jejich problémů. Ve výzkumu částečně pokračuji a připravuji další článek, který bych opět rád zveřejnil v nějakém dobrém bioinformatickém časopise. Vedle toho se však především věnuji magisterskému studiu na ETH v Curychu a také pracuji na částečný úvazek v AI startupu. Přestože moje aktuální práce již s bioinformatikou nesouvisí, nevylučuji, že se k této oblasti v budoucnu opět vrátím.
Bakalářská práce: Masked superstrings for efficient k-mer set representation and indexing
Odkazy:
Nástroj na výpočet reprezentace (GitHub)
Preprint článku o maskovaných nadřetězcích
Preprint článku k množinovým operacím s maskovanými nadřetězci
Původní materiál Informatické sekce



