
Svět přírodních molekul je z velké části neprobádaný, přestože v něm mohou být skryty klíče k léčbě mnoha nemocí. Denys Boyko se ve své bakalářské práci rozhodl tento proces urychlit pomocí umělé inteligence. Využil k tomu principy podobné těm, které generují obrázky, a aplikoval je na tzv. hmotnostní spektra.
Jeho metoda „Discrete Diffusion“ dokáže z náhodného shluku atomů postupně vytvořit smysluplnou strukturu molekuly, aniž by k tomu potřebovala tradiční slovníky. Přečtěte si, jaké to je trénovat modely na obřích datech s pomocí Metacentra a jak se studentovi Matfyzu podařilo dosáhnout špičkových výsledků ve spolupráci s odborníky z ČVUT.
Popište nám svůj projekt...
Cílem projektu je vyvinout metodu pro generování malých molekul z tandemových hmotnostních spekter a molekulových formulí.
Co vás inspirovalo k tomu, abyste se zaměřil právě na generování molekul?
Chtěl jsem pracovat na něčem, co může být ve skutečnosti užitečné (například pro medicínu), a toto téma to splňovalo. Navíc je poměrně nové a daleko od definitivního vyřešení. V současnosti dosahuje úspěšnost nejlepších metod přibližně 4 %. Chtěl bych zmínit, že naši studenti nemusejí témata prací hledat jenom na Matfyzu. Práci mi vedl Josef Šivic z ČVUT, který je externím pracovníkem Matfyzu. Mým druhým školitelem byl Roman Bushuiev, který je Ph.D. studentem na ČVUT.
Můžete vysvětlit, jaký konkrétní přínos nebo využití má vaše práce?
Velkou motivací mojí práce je skutečnost, že svět přírodních molekul máme velmi málo prozkoumaný (neznáme jejich struktury), což je škoda, protože mnoho látek z přírody by se dalo dobře využít. Výhodou tandemové hmotnostní spektrometrie je, že je rychlá a zároveň měří spektra většiny molekul ze vzorců, které jí zadáte. Bohužel, přečíst strukturu molekuly ze spektra je velmi netriviální úkol, který se v současnosti řeší pomocí „slovníků“ typu spektrum → struktura. Tyto slovníky jsou však značně omezené, zejména ty veřejné, proto by byl systém pro generování struktur bez použití slovníků velmi užitečný. Takový systém by pak bylo možné využít prakticky kdekoliv, kde je potřeba analyzovat nějaký vzorek, například krev.
S jakými technologiemi jste pracoval, jaké metody jste využíval, a proč zrovna tyto?
Hlavním základem mé práce byla metoda Discrete Diffusion. Jedná se o difuzní model, který je svým principem podobný modelům pro generování obrázků. Proces začíná od šumu a končí smysluplným výsledkem. V tomto případě však začíná náhodným shlukem atomů, které jsou náhodně propojené, a s každou iterací model mění jednotlivé atomy i vazby mezi nimi. Pro zájemce: primární knihovnou pro strojové učení byl PyTorch s nadstavbou PyTorch Lightning. Pro práci s molekulami byl použit RDKit. Kód a všechny potřebné knihovny jsou dostupné na GitLabu, kde je k dispozici i samotný text práce.
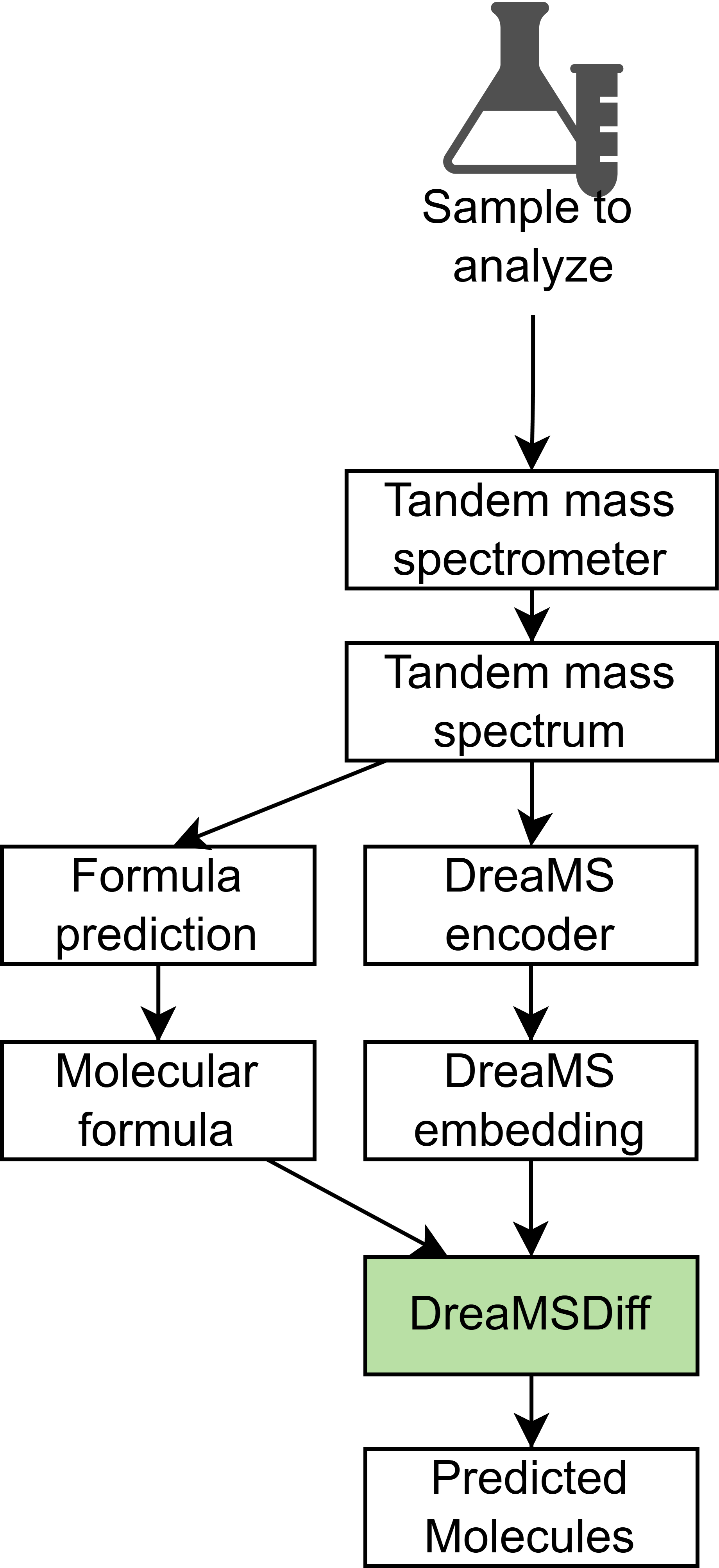
Schéma celého procesu, ve kterém je využita moje metoda (zelený
obdélník označuje program, který na základě formule a DreaMS embeddings
generuje výsledné molekuly)
Co bylo během psaní vaší práce nejtěžší, bylo něco, na čem jste se zasekl, nějaká cesta, co nikam nevedla? Je něco, co byste zpětně udělal jinak?
Bylo toho docela dost. Největší výzvou byla samotná velikost dat a náročnost modelu. Pro trénování jsem musel využívat infrastrukturu Metacentra a GPU s pamětí alespoň 40 GB, k čemuž bylo potřeba přibližně 200 GB RAM, aby bylo možné s daty vůbec manipulovat. Na takové nároky jsem jako student nebyl zvyklý. Velkou část času mi tedy zabralo jen samotné zpracování dat a zajišťování dostatečného výpočetního výkonu. Trénování jednoho modelu trvalo minimálně čtyři dny a podobně dlouho probíhalo i jeho testování. Experimenty tak byly extrémně časově náročné – pokud se během procesu cokoliv pokazilo, znamenalo to zdržení o několik dní. Zkoušel jsem sice vytvořit menší model, který by byl rychlejší a méně náročný na paměť, ale ten nakonec nedosahoval tak dobrých výsledků jako verze větší. Specifickou součástí projektu bylo také to, že jsem model nutil počítat s explicitními vodíky, což podle mých znalostí nikdo jiný v této oblasti nedělá. Zpětně si myslím, že touto cestou už bych se nejspíš nevydal. Výrazně to totiž zvyšuje komplexitu celého systému – do modelu vstupuje klidně dvakrát až třikrát více atomů a tím i mnohem více vazeb, se kterými se stroj musí vypořádat. Přestože to má své teoretické výhody, které v práci popisuji, pro model i hardware je to obrovská zátěž.
Jakým způsobem jste ověřoval výsledky své práce?
Model jsem trénoval a testoval pomocí datasetu MassSpecGym, který je rozdělen na trénovací, validační a testovací části. MassSpecGym je benchmarkový systém určený právě pro úlohu, kterou můj projekt řešil. Obsahuje také definované metriky pro porovnávání různých modelů a měření jejich efektivity.
Proces generování molekul od úplně náhodného grafu, který se postupně mění, než vznikne smysluplná molekula
Co považujete za nejdůležitější výsledek nebo závěr své práce?
Podařilo se mi dosáhnout state-of-the-art výsledku v jedné důležité metrice a konkurenceschopných výsledků v několika dalších. Zároveň si cením i zkušenosti s prací na tomto projektu a všeho, co jsem se během něj naučil.
Máte pocit, že vaše práce může být inspirací pro další studenty nebo odborníky v dané oblasti?
Rozhodně si myslím, že moje práce může sloužit jako základ pro navazující výzkum, protože nabízí hned několik možností, jak ji dále vylepšovat.
Bakalářská práce



