
Umělá inteligence, která dokáže na základě krátké vizuální stopy určit hudební žánr anebo z obrovské tabulky čísel odvodit, jak spolu obsažená data souvisejí. Vědci z Katedry softwarového inženýrství MFF UK pod vedením profesora Tomáše Skopala testovali možnosti využití umělé inteligence vytrénované na běžných obrázcích z internetu. Jejich výzkum, který podpořila Grantová agentura ČR, otevírá dveře k novému, jednoduššímu způsobu analýzy velkých datových kolekcí.
| Název projektu | Hluboké vizuální reprezentace nestrukturovaných dat |
|---|---|
| Řešitel | Tomáš Skopal |
| Typ projektu | GAČR standardní projekt |
| Období řešení | 2022–2024 |
| Hodnocení GAČR | vynikající |
V projektu Hluboké vizuální reprezentace nestrukturovaných dat výzkumníci testovali možnosti využití běžných předtrénovaných vizuálních modelů strojového učení. „Vizuálním modelem myslíme například hlubokou konvoluční neuronovou síť natrénovanou na anotovaných kolekcích běžných obrázků dostupných na webu,“ upřesňuje vedoucí projektu prof. Tomáš Skopal. Mezi takové modely patří například AlexNet z roku 2012, historicky nejstarší hluboká neuronová síť určená k rozpoznávání obrázků.
Vizuální modely se standardně využívají ke klasifikaci obrázků pomocí klíčových slov a také jako sémantické reprezentace pro účely datové analýzy. „V praxi to znamená, že máte například fotografii motorkáře na silnici, provedete inferenci – tedy fotografii ‚proženete‘ neuronovou sítí – a model vám fotografii oklasifikuje klíčovými slovy ‚motorka‘, ‚závodník, ‚silnice‘ apod. Vedle toho ale taky můžete z dané inference ‚sejmout‘ i tzv. feature vector, tedy vnitřní reprezentaci fotografie motorkáře, když probíhala modelem. Tyto vektory pak mohou sloužit jako sémantické reprezentace (otisk/fingerprint) původních dat a fotek pro různé účely datové analýzy, například vyhledávání, shlukování,“ vysvětluje prof. Skopal.
Jeho tým však tyto modely otestoval ještě jinak. Na modely trénované běžnými fotkami výzkumníci aplikovali vizualizace původně nevizuálních dat. Jinými slovy, do obrazové podoby převedli zvuky, diagnózy pacientů, klasifikace molekul nebo další datové sady a zkoumali, jak si s nimi modely poradí.
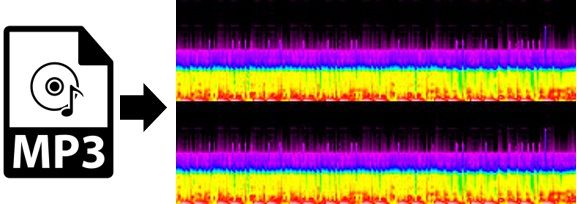
Samotnému projektu předcházel průzkum, do kterého se zapojili studenti Matfyzu. Ti zkoušeli vizualizovat hudební záznamy a jejich „obrazy“ následně přiřazovat určitému hudebnímu žánru. „Studenti si stáhli spoustu MP3 nahrávek různých žánrů, převedli je do spektrogramové vizualizace a každou z nich analyzovali zmíněnými modely, např. AlexNetem, který podobné ‚divné‘ obrázky nikdy neviděl. Následně jsme nasbírali pro tyto vizualizace feature vektory, které jsme použili pro shlukování,“ popisuje prof. Skopal. „A ukázalo se, že shluky spektrogramů přesně odpovídají hudebním žánrům původních MP3! Jinými slovy, AlexNet, dnes již archaický model, je schopen generalizace. Dokáže reprezentovat nejen sémantiku schovanou v datech, která ‚už viděl‘, ale i sémantiku kódovanou v obrázcích, které ‚nikdy neviděl‘.“
Na základě tohoto pokusu vědci zkoumali obecné možnosti využití vizuálních hlubokých modelů pro (původně) nevizuální data. Zjistili, že výše popsaný způsob přenosu znalosti z domény do domény (tzv. transfer learning) funguje v řadě oblastí, jako jsou například biometrika (identifikace pomocí chůze či stylu psaní na klávesnici), detekce plagiátů binárního kódu (v programech), klasifikace EEG signálu, pacientská data (stanovení diagnózy) či klasifikace molekul.
Tým se zaměřil také na to, zda jsou vizualizace pochopitelné i pro běžného lidského pozorovatele/uživatele, a jestli je tedy možné vyrábět univerzální vizuální reprezentace rozmanitých dat, které umožní strukturovat velké datové kolekce z pohledu lidské i strojové vizuální kognice. „Zjistili jsme například, že nejefektivnější vizualizací pro pochopení jak člověkem, tak i strojem jsou tzv. chernoff faces a jejich modernější AI varianty GAN faces.“

Chernoff faces je metoda, jak vizualizovat vícerozměrná data, která vznikla v 70. letech minulého století a vychází z myšlenky, že lidský mozek dokáže dobře vnímat tváře. Data jsou pomocí této techniky zobrazována jako obličej, jehož tvar a rysy odpovídají hodnotám proměnných. „Sémantika původních nevizuálních dat se v těch jednodušších cartoon-obličejích kóduje např. velikostí a rozmístěním očí, barvou obličeje, šířkou hlavy, tvarem nosu apod. A protože člověk je evolucí vycvičen vnímat obličej komplexně, je schopen různá komplexní data vidět jako různé obličeje a na základě toho si segmentovat datový prostor, aniž by musel úmorně interpretovat různé parametry, které k té komplexitě přispívají. Jinými slovy, když uživatel mrkne okem na matici různých obličejů, okamžitě má hrubou představu o distribuci dat v prostoru. Samozřejmě, že jednotlivé grimasy obličeje nemají jednoduchou interpretaci, pouze umožňují rozlišovat různá data od sebe, případně shlukovat na základě podobnosti grimas. Totéž se děje v případě GAN faces, jenom je to celé složitější. Zajímavé je, že jak lidští uživatelé, tak AI agenti (strojové modely) jsou schopni ‚vidět‘ v takových reprezentacích podobné vlastnosti, tedy rozlišovat sémantiku v původních datech podobně,“ říká prof. Skopal.
Výzkum přinesl vhled do procesu návrhu a kognice vizuálních datových reprezentací, které mohou být užitečné tam, kde jsou analytické reprezentace pro člověka i stroj nečitelné. „Například rozsáhlá tabulka záznamů numerických hodnot o 1000 sloupcích má tzv. vysokou vnitřní dimenzi, kdy pro člověka jde jen o změť čísel. Sloupce samostatně žádnou velkou sémantickou informaci nenesou, ale až kombinace všech sloupců dostane smysl. Ve vizuální reprezentaci, např. obličejové, lze tuto sémantiku kognitivně vnímat jako jeden komplexní vjem (pro člověka i stroj),“ dodává prof. Skopal.
Ve videu se můžete podívat na jednotlivé reprezentace, které jsou přehlednější než tabulka o tisíci sloupcích.
Studentské práce, které přispěly k projektu:
| Ivana Sixtová | VISAnt: Unsupervised data exploration with Chernoff faces – příspěvek na konferenci SISAP 25 |
| Patrik Veselý | Similarity Models for Content – based Video Retrieval |
| Patrik Dokoupil | Generating synthetic data for an assembly of police lineups |
| Richard Savčinský | Visual Explanations in Music Recommender Systems |
| Martin Spišák | Sparse Approximate Inverse for Enhanced Scalability in Recommender Systems |
| Zuzana Vopálková | Extension of the video retrieval system PraK |
Články k projektu:
| Unified Visual-Aware Representations for Data Analytics |
| Visualizations for universal deep-feature representations: survey and taxonomy |
| Visual Representations for Data Analytics: User Study |
Další práce jsou dostupné na stránce projektu zde.